-
使用 最后一层全连接层输入的 feature 作为处理对象,即缩小这一 feature 的类内距离
-
实现 feature 和 label 的对齐,主要解决了 预测重复、预测漏字 时的对齐问题(需要tf1.15)
-
增加对关键指标的计算和追踪,训练过程更直观,方便 debug (需要tf1.15)

center 之间的距离

字符距离自己center、形近字center的距离


经过训练,字符距离差增大,预测置信度和距离差拥有一定相关性
- 增加 feature 的可视化,使用 tensorboard 的 embedding projector,方便debug
# 生成 embedding 图
python -m libs.projector --model=your_model_path --file=your_label_file_path --dir=your_log_dir
# 启动 tensorboard
tensorboard --logdir=your_log_dir
iter=0

iter=100

iter=500
本项目用自己想法实现阿里云栖大会中,阿里团队提到的ctc+centerloss来解决相近字的问题 pdf百度网盘链接: https://pan.baidu.com/s/13370jLcBblmqvwfprHPYXw 提取码: mejj
pip install -r requirements.txt
- 链接: 链接:https://pan.baidu.com/s/12oa1QcjaWiLb7Xsiz7aqbg 提取码:6Dw9
1 先用https://github.com/Sanster/tf_crnn 的crnn训练2.对原始crnn训练到val acc 到95% loss 0.1左右,或者直至有满意的效果。3.用gen_CR_data.py,用上面训练好的模型文件进行新的label生成4.修改 crnn.py 文件 109行 centerloss 的权重为0。00001进行crnn 的训练python train.py5.训练到val acc 95% 或者到自己对效果满意- 1.先用https://github.com/Sanster/tf_crnn 的crnn训练
- 2.对原始crnn训练到val acc 到95%以上 loss 0.1左右,或者直至有满意的效果。
- 3.把模型作为此工程pretrain model
python train.py
python test.py
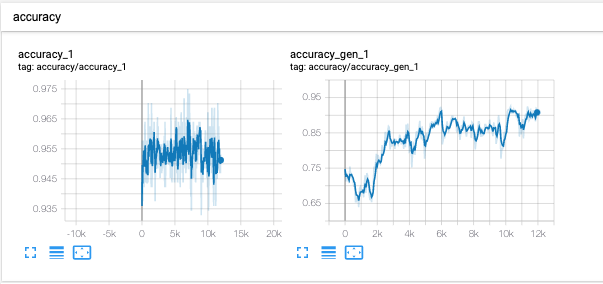
- 左面图为全量数据 可以看到对于全量也有一点提升
- 右面图为近似字数据 对于形近字提升有15个点。提升明显并且还有增长空间

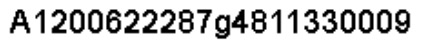
- 'A1200622287g4811330009'
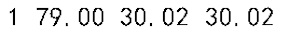
- '1 79.00 30.02 30.02'
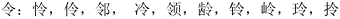
- '令:怜,伶,邻, 冷,领,龄,铃,岭,玲,拎'
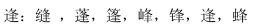
- '逢:缝,蓬,篷,峰,锋,逢,蜂'
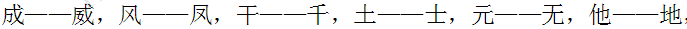
- '成一一威,风一一凤,干一一千,土一一士,元一一无,他一一地'
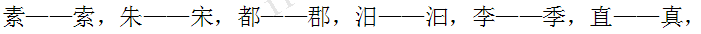
- '素一一索,朱一一宋,都一一郡,汨一一汩,李一一季,直一一真,'






训练数据与预训练模型 关注微信公众账号 hulugeAI 留言:ctc 获取 线下wx交流群入门券
copy right huluge