NewsSpider 是一个舆情信息获取与可视化平台,基于 GNE(General News Extractor,通用新闻正文抽取)模块,抽取 400+ 个舆情站点的正文内容、标题、作者、发布时间、图片地址和正文所在的标签源代码等信息。项目主干技术覆盖python、scrapy、scrapyd、scrapydweb(开源管理平台)、mysql、redis,支持任意数量的爬虫一键运行、定时任务、批量删除、一键部署,并且可以实现爬虫监控可视化、配置集群爬虫分配策略、现成的docker一键部署等功能。 最近一次完全放开条件可抓500W+有效数据。
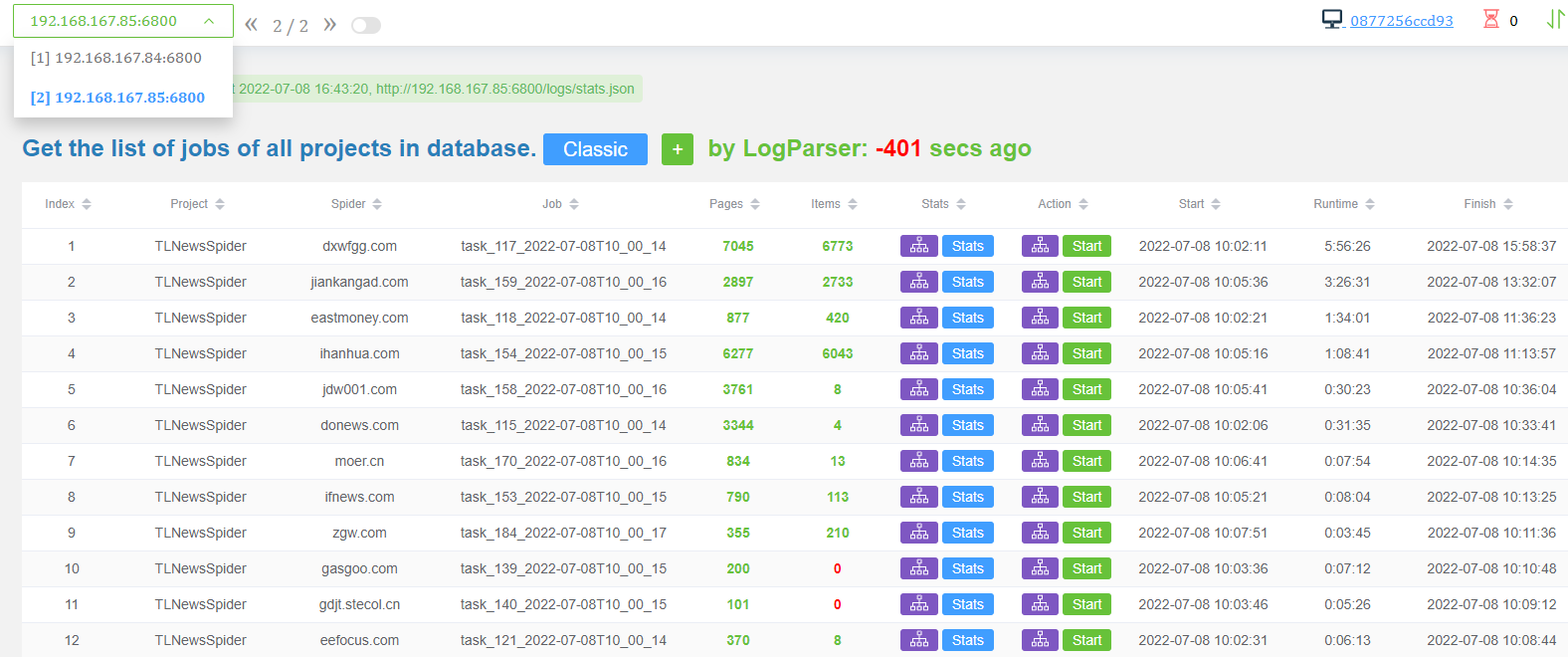
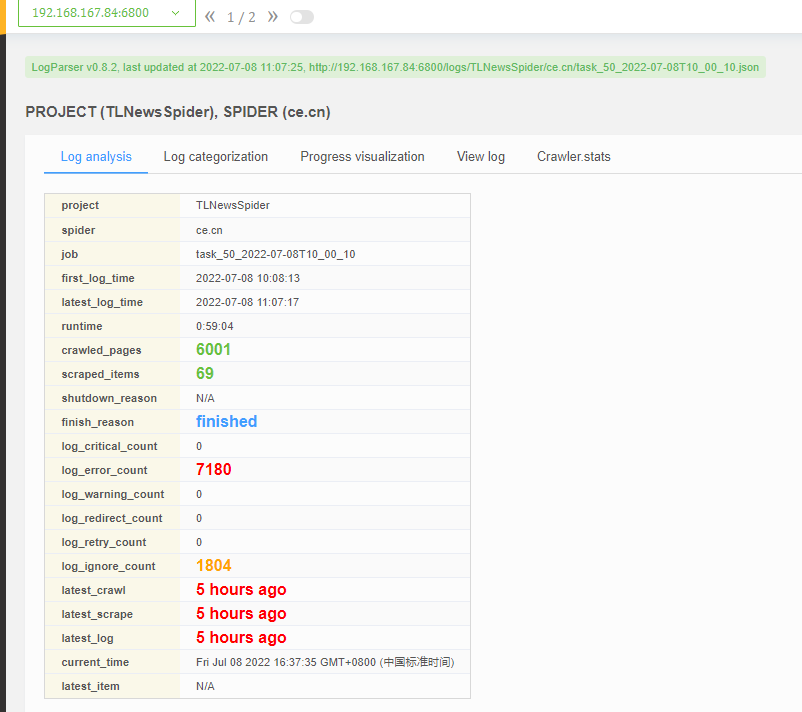
主干技术:python、scrapy、scrapyd、scrapydweb(开源管理平台)、mysql、redis
爬虫可配置中间件:
- redis去重中间件
- 请求重试中间件
- 代理中间件
- 爬虫详情信息定时推送至第三方小程序(微信公众号、飞书等-待开发)
爬虫可配置数据管道:
- 数据前处理
- 数据过滤清洗
- 数据存储入库
- 数据入redis(同redis去重)
其他功能:
- 数据推送至 Kafaka
- 爬虫可选限制(时间范围、翻页数量)
其他scrapy高级功能
需上传项目至服务器固定目录: /home/spider_workplace/
sudo权限下
yum update
yum install -y yum-utils
yum install docker
# 使用国内镜像仓库
curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s https://registry.docker-cn.com
# 重启
systemctl restart docker
# 启动测试
docker run hello-world参考: https://blog.csdn.net/xinle0320/article/details/124205608
curl -L "https://github.com/docker/compose/releases/download/1.25.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
# 添加权限
chmod +x /usr/local/bin/docker-compose- github 离线下载对应版本 docker-compose
- 上传至服务目录: /usr/local/bin/docker-compose
- 修改权限:chmod +x /usr/local/bin/docker-compose
1. 添加需要初始化的数据库 sql 表结构文件 > 重命名init.sql 上传
# 数据库存储目录
mv ./docker_yml/database /data/ && cd /data/database
# 安装启动
docker-compose up -d
# 检查是否启动成功
docker-compose pscd ./docker_yml/news_crawl
# 安装启动
docker-compose up -d
# 检查是否启动成功
docker-compose ps
# 启动失败参考: 4、修改scrapydweb 配置、添加集群等# 根据报错或者其他需求修改 scrapydweb_settings_v10.py 配置文件
vim /home/spider_workplace/TLNewsCrawl/TLNewsSpider/scrapyd_web_manager/scrapydweb_settings_v10.py
# 重建容器
docker-compose down
docker-compose up -d
# 查看日志:
docker-compose logs基于scrapydweb的公开接口, 批量管理爬虫任务的调度,免去前端页面的单个点击操作 Note: 1. 操作之前分好可用节点 和 host 集群模式下**多个节点爬虫任务数量的划分策略**有两种:
- def: group_spiders_by_chars 通过首字母等分爬虫
- def: group_spiders_by_length 通过爬虫数量等分 (目前使用的这种)
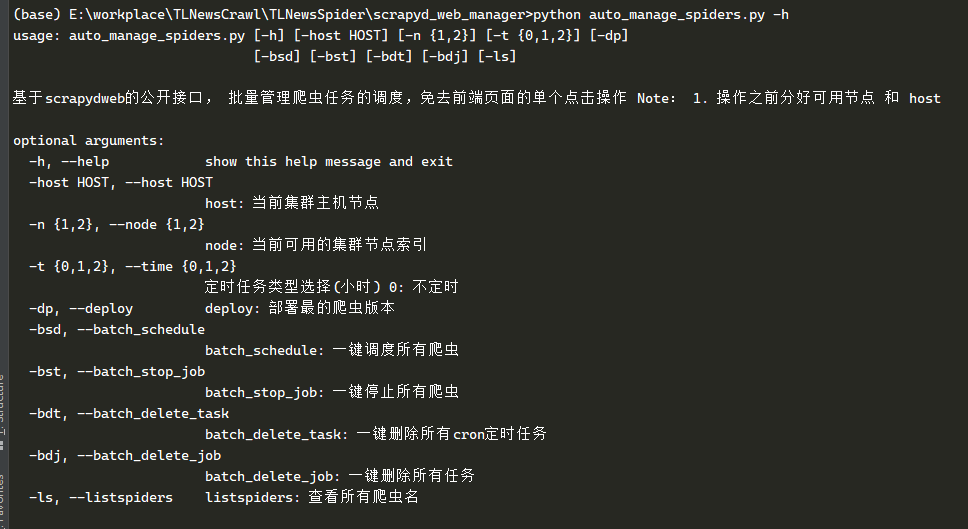
>> python auto_manage_spiders.py -h
usage: auto_manage_spiders.py [-h] [-host HOST] [-n {1,2}] [-t {0,1,2}] [-dp]
[-bsd] [-bst] [-bdt] [-bdj] [-ls]
基于scrapydweb的公开接口, 批量管理爬虫任务的调度,免去前端页面的单个点击操作 Note: 1. 操作之前分好可用节点 和 host
optional arguments:
-h, --help show this help message and exit
-host HOST, --host HOST
host: 当前集群主机节点
-n {1,2}, --node {1,2}
node: 当前可用的集群节点索引
-t {0,1,2}, --time {0,1,2}
定时任务类型选择(小时) 0: 不定时
-dp, --deploy deploy: 部署最的爬虫版本
-bsd, --batch_schedule
batch_schedule: 一键调度所有爬虫
-bst, --batch_stop_job
batch_stop_job: 一键停止所有爬虫
-bdt, --batch_delete_task
batch_delete_task: 一键删除所有cron定时任务
-bdj, --batch_delete_job
batch_delete_job: 一键删除所有任务
-ls, --listspiders listspiders: 查看所有爬虫名NOTE:提示
-
在网络互通的条件下任意位置执行该脚本;否则在容器内执行。
-
--host 参数默认值设置为当前主节点 (必要)
-
host_list: 列表加上当前所有节点 host (必要)
-
cron_list: 按需求设置定时任务需要的cron参数 -- 当前为按小时定时,有需要可自行修改 (非必要)
# 批量启动节点1的爬虫
python auto_manage_spiders.py -n 1
# 批量启动节点2的爬虫、同时添加到定时任务
python auto_manage_spiders.py -n 2 -t 1
# 部署新的爬虫版本
python auto_manage_spiders.py -dp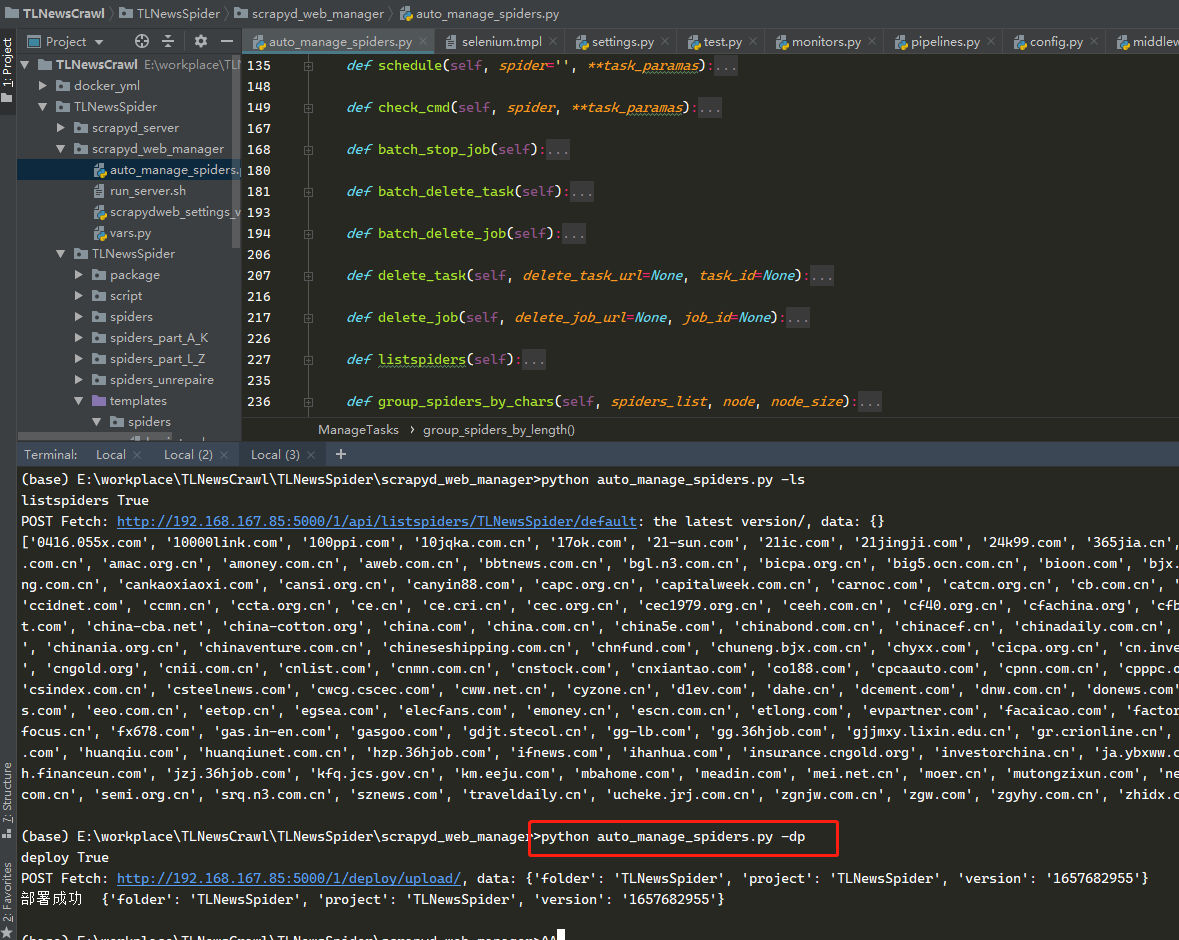
ps: 此项目核心是整体大框架的部署应用和一些高级模块应用
- 如果本项目对你的工作、学习有帮助 请动动你们发财的小手指
- 给作者后续更多开源的动力 ↓ ↓ ↓
- 建了一个python技术交流小群 各位卷王大佬们加V进群 -> 加的人多了 请备注经验年限和地域 感恩! 手动emoj
 |