作者:骆昊
说明:中国大陆用户如果访问 GitHub 比较慢的话,可以关注我的知乎号 Python-Jack,上面的“从零开始学Python”专栏比较适合初学者,其他的专栏如“数据思维和统计思维”、“基于Python的数据分析”、“说走就走的AI之旅”等也在持续创作和更新中,欢迎大家关注、点赞和评论。大家在学习过程中如果遇到一些棘手的问题或者需要相关的学习资源,可以加入下面的 QQ 交流群,三个群是一样的加入一个即可,请不要重复加群,也不要在群里发布广告和其他色情、低俗或敏感内容。如果缺乏自律性,有付费学习的需求,可以添加我的私人微信(jackfrued)私聊,备注好自己的称呼和需求,我会给大家提供一些学习方案和职业规划方面的指导。

配套的视频在抖音和B站持续更新中,有兴趣的小伙伴可以关注我的抖音(Python-Jack)或B站(骆昊jackfrued),最近刚刚起号,还希望大家多多支持,非常感谢您!

简单的说,Python是一个“优雅”、“明确”、“简单”的编程语言。
- 学习曲线低,非专业人士也能上手
- 开源系统,拥有强大的生态圈
- 解释型语言,完美的平台可移植性
- 动态类型语言,支持面向对象和函数式编程
- 代码规范程度高,可读性强
Python在以下领域都有用武之地。
- 后端开发 - Python / Java / Go / PHP
- DevOps - Python / Shell / Ruby
- 数据采集 - Python / C++ / Java
- 量化交易 - Python / C++ / R
- 数据科学 - Python / R / Julia / Matlab
- 机器学习 - Python / R / C++ / Julia
- 自动化测试 - Python / Shell
作为一名Python开发者,根据个人的喜好和职业规划,可以选择的就业领域也非常多。
- Python后端开发工程师(服务器、云平台、数据接口)
- Python运维工程师(自动化运维、SRE、DevOps)
- Python数据分析师(数据分析、商业智能、数字化运营)
- Python数据科学家(机器学习、深度学习、算法专家)
- Python爬虫工程师(不推荐此赛道!!!)
- Python测试工程师(自动化测试、测试开发)
说明:目前,数据科学赛道是非常热门的方向,因为不管是互联网行业还是传统行业都已经积累了大量的数据,各行各业都需要数据科学家从已有的数据中发现更多的商业价值,从而为企业的决策提供数据的支撑,这就是所谓的数据驱动决策。
给初学者的几个建议:
- Make English as your working language. (让英语成为你的工作语言)
- Practice makes perfect. (熟能生巧)
- All experience comes from the mistakes you've made. (所有的经验都源于你犯过的错误)
- Don't be a freeloader. (不要当伸手党)
- Either outstanding or out. (要么出众,要么出局)
Day01 - 初识Python
- Python简介
- Python编年史
- Python优缺点
- Python应用领域
- 安装Python环境
- Windows环境
- macOS环境
Day02 - 第一个Python程序
- 编写代码的工具
- 你好世界
- 注释你的代码
Day03 - Python语言中的变量
- 一些常识
- 变量和类型
- 变量命名
- 变量的使用
Day04 - Python语言中的运算符
- 算术运算符
- 赋值运算符
- 比较运算符和逻辑运算符
- 运算符和表达式应用
- 华氏和摄氏温度转换
- 计算圆的周长和面积
- 判断闰年
Day05 - 分支结构
- 使用if和else构造分支结构
- 使用match和case构造分支结构
- 分支结构的应用
- 分段函数求值
- 百分制成绩转换成等级
- 计算三角形的周长和面积
Day06 - 循环结构
- for-in循环
- while循环
- break和continue
- 嵌套的循环结构
- 循环结构应用举例
- 判断素数
- 最大公约数
- 猜数字游戏
Day07 - 分支和循环结构的应用
- 例子1:100以内的素数
- 例子2:斐波那契数列
- 例子3:寻找水仙花数
- 例子4:百钱百鸡问题
- 例子5:CRAPS赌博游戏
Day08 - 常用数据结构之列表-1
- 创建列表
- 列表的运算
- 元素的遍历
Day09 - 常用数据结构之列表-2
- 列表的方法
- 添加和删除元素
- 元素位置和频次
- 元素排序和反转
- 列表生成式
- 嵌套列表
- 列表的应用
Day10 - 常用数据结构之元组
- 元组的定义和运算
- 打包和解包操作
- 交换变量的值
- 元组和列表的比较
Day11 - 常用数据结构之字符串
- 字符串的定义
- 转义字符
- 原始字符串
- 字符的特殊表示
- 字符串的运算
- 拼接和重复
- 比较运算
- 成员运算
- 获取字符串长度
- 索引和切片
- 字符的遍历
- 字符串的方法
- 大小写相关操作
- 查找操作
- 性质判断
- 格式化
- 修剪操作
- 替换操作
- 拆分与合并
- 编码与解码
- 其他方法
Day12 - 常用数据结构之集合
- 创建集合
- 元素的变量
- 集合的运算
- 成员运算
- 二元运算
- 比较运算
- 集合的方法
- 不可变集合
Day13 - 常用数据结构之字典
- 创建和使用字典
- 字典的运算
- 字典的方法
- 字典的应用
Day14 - 函数和模块
- 定义函数
- 函数的参数
- 位置参数和关键字参数
- 参数的默认值
- 可变参数
- 用模块管理函数
- 标准库中的模块和函数
Day15 - 函数的应用
- 例子1:随机验证码
- 例子2:判断素数
- 例子3:最大公约数和最小公倍数
- 例子4:数据统计
- 例子5:双色球随机选号
Day16 - 函数使用进阶
- 高阶函数
- Lambda函数
- 偏函数
Day17 - 函数高级应用
- 装饰器
- 递归调用
Day18 - 面向对象编程入门
- 类和对象
- 定义类
- 创建和使用对象
- 初始化方法
- 面向对象的支柱
- 面向对象案例
- 例子1:数字时钟
- 例子2:平面上的点
Day19 - 面向对象编程进阶
- 可见性和属性装饰器
- 动态属性
- 静态方法和类方法
- 继承和多态
Day20 - 面向对象编程应用
- 扑克游戏
- 工资结算系统
Day21 - 文件读写和异常处理
- 打开和关闭文件
- 读写文本文件
- 异常处理机制
- 上下文管理器语法
- 读写二进制文件
Day22 - 对象的序列化和反序列化
- JSON概述
- 读写JSON格式的数据
- 包管理工具pip
- 使用网络API获取数据
Day23 - Python读写CSV文件
- CSV文件介绍
- 将数据写入CSV文件
- 从CSV文件读取数据
Day24 - Python读写Excel文件-1
- Excel简介
- 读Excel文件
- 写Excel文件
- 调整样式
- 公式计算
Day25 - Python读写Excel文件-2
- Excel简介
- 读Excel文件
- 写Excel文件
- 调整样式
- 生成统计图表
Day26 - Python操作Word和PowerPoint文件
- 操作Word文档
- 生成PowerPoint
Day27 - Python操作PDF文件
- 从PDF中提取文本
- 旋转和叠加页面
- 加密PDF文件
- 批量添加水印
- 创建PDF文件
Day28 - Python处理图像
- 入门知识
- 用Pillow处理图像
- 使用Pillow绘图
Day29 - Python发送邮件和短信
- 发送电子邮件
- 发送短信
Day30 - 正则表达式的应用
- 正则表达式相关知识
- Python对正则表达式的支持
- 例子1:输入验证
- 例子2:内容提取
- 例子3:内容替换
- 例子4:长句拆分
- 重要知识点
- 数据结构和算法
- 函数的使用方式
- 面向对象相关知识
- 迭代器和生成器
- 并发编程
- 用HTML标签承载页面内容
- 用CSS渲染页面
- 用JavaScript处理交互式行为
- Vue.js入门
- Element的使用
- Bootstrap的使用
- 操作系统发展史和Linux概述
- Linux基础命令
- Linux中的实用程序
- Linux的文件系统
- Vim编辑器的应用
- 环境变量和Shell编程
- 软件的安装和服务的配置
- 网络访问和管理
- 其他相关内容
Day36 - 关系型数据库和MySQL概述
- 关系型数据库概述
- MySQL简介
- 安装MySQL
- MySQL基本命令
Day37 - SQL详解之DDL
- 建库建表
- 删除表和修改表
Day38 - SQL详解之DML
- insert操作
- delete操作
- update操作
Day39 - SQL详解之DQL
- 投影和别名
- 筛选数据
- 空值处理
- 去重
- 排序
- 聚合函数
- 嵌套查询
- 分组操作
- 表连接
- 笛卡尔积
- 内连接
- 自然连接
- 外连接
- 窗口函数
- 定义窗口
- 排名函数
- 取数函数
Day40 - SQL详解之DCL
- 创建用户
- 授予权限
- 召回权限
Day41 - MySQL新特性
- JSON类型
- 窗口函数
- 公共表表达式
Day42 - 视图、函数和过程
- 视图
- 使用场景
- 创建视图
- 使用限制
- 函数
- 内置函数
- 用户自定义函数(UDF)
- 过程
- 创建过程
- 调用过程
Day43 - 索引
- 执行计划
- 索引的原理
- 创建索引
- 普通索引
- 唯一索引
- 前缀索引
- 复合索引
- 注意事项
Day44 - Python接入MySQL数据库
- 安装三方库
- 创建连接
- 获取游标
- 执行SQL语句
- 通过游标抓取数据
- 事务提交和回滚
- 释放连接
- 编写ETL脚本
Day45 - 大数据平台和HiveSQL
- Hadoop生态圈
- Hive概述
- 准备工作
- 数据类型
- DDL操作
- DML操作
- 数据查询
Day46 - Django快速上手
- Web应用工作机制
- HTTP请求和响应
- Django框架概述
- 5分钟快速上手
Day47 - 深入模型
- 关系型数据库配置
- 使用ORM完成对模型的CRUD操作
- 管理后台的使用
- Django模型最佳实践
- 模型定义参考
Day48 - 静态资源和Ajax请求
- 加载静态资源
- Ajax概述
- 用Ajax实现投票功能
Day49 - Cookie和Session
- 实现用户跟踪
- cookie和session的关系
- Django框架对session的支持
- 视图函数中的cookie读写操作
Day50 - 报表和日志
- 通过
HttpResponse修改响应头 - 使用
StreamingHttpResponse处理大文件 - 使用
xlwt生成Excel报表 - 使用
reportlab生成PDF报表 - 使用ECharts生成前端图表
Day51 - 日志和调试工具栏
- 配置日志
- 配置Django-Debug-Toolbar
- 优化ORM代码
Day52 - 中间件的应用
- 什么是中间件
- Django框架内置的中间件
- 自定义中间件及其应用场景
Day53 - 前后端分离开发入门
- 返回JSON格式的数据
- 用Vue.js渲染页面
Day54 - RESTful架构和DRF入门
- REST概述
- DRF库使用入门
- 前后端分离开发
- JWT的应用
Day55 - RESTful架构和DRF进阶
- 使用CBV
- 数据分页
- 数据筛选
Day56 - 使用缓存
- 网站优化第一定律
- 在Django项目中使用Redis提供缓存服务
- 在视图函数中读写缓存
- 使用装饰器实现页面缓存
- 为数据接口提供缓存服务
Day57 - 接入三方平台
- 文件上传表单控件和图片文件预览
- 服务器端如何处理上传的文件
Day58 - 异步任务和定时任务
- 网站优化第二定律
- 配置消息队列服务
- 在项目中使用Celery实现任务异步化
- 在项目中使用Celery实现定时任务
Day59 - 单元测试
Day60 - 项目上线
- Python中的单元测试
- Django框架对单元测试的支持
- 使用版本控制系统
- 配置和使用uWSGI
- 动静分离和Nginx配置
- 配置HTTPS
- 配置域名解析
Day61~65 - 爬虫开发
Day61 - 网络数据采集概述
- 网络爬虫的概念及其应用领域
- 网络爬虫的合法性探讨
- 开发网络爬虫的相关工具
- 一个爬虫程序的构成
- 使用
requests三方库实现数据抓取 - 页面解析的三种方式
- 正则表达式解析
- XPath解析
- CSS选择器解析
Day64 - 使用Selenium抓取网页动态内容
- 安装Selenium
- 加载页面
- 查找元素和模拟用户行为
- 隐式等待和显示等待
- 执行JavaScript代码
- Selenium反爬破解
- 设置无头浏览器
Day65 - 爬虫框架Scrapy简介
- Scrapy核心组件
- Scrapy工作流程
- 安装Scrapy和创建项目
- 编写蜘蛛程序
- 编写中间件和管道程序
- Scrapy配置文件
Day66 - 数据分析概述
- 数据分析师的职责
- 数据分析师的技能栈
- 数据分析相关库
Day67 - 环境准备
- 安装和使用anaconda
- conda相关命令
- 安装和使用jupyter-lab
- 安装和启动
- 使用小技巧
Day68 - NumPy的应用-1
- 创建数组对象
- 数组对象的属性
- 数组对象的索引运算
- 普通索引
- 花式索引
- 布尔索引
- 切片索引
- 案例:使用数组处理图像
Day69 - NumPy的应用-2
- 数组对象的相关方法
- 获取描述性统计信息
- 其他相关方法
Day70 - NumPy的应用-3
- 数组的运算
- 数组跟标量的运算
- 数组跟数组的运算
- 通用一元函数
- 通用二元函数
- 广播机制
- Numpy常用函数
Day71 - NumPy的应用-4
- 向量
- 行列式
- 矩阵
- 多项式
Day72 - 深入浅出pandas-1
- 创建Series对象
- Series对象的运算
- Series对象的属性和方法
Day73 - 深入浅出pandas-2
- 创建DataFrame对象
- DataFrame对象的属性和方法
- 读写DataFrame中的数据
Day74 - 深入浅出pandas-3
- 数据重塑
- 数据拼接
- 数据合并
- 数据清洗
- 缺失值
- 重复值
- 异常值
- 预处理
Day75 - 深入浅出pandas-4
- 数据透视
- 获取描述性统计信息
- 排序和头部值
- 分组聚合
- 透视表和交叉表
- 数据呈现
Day76 - 深入浅出pandas-5
- 计算同比环比
- 窗口计算
- 相关性判定
Day77 - 深入浅出pandas-6
- 索引的使用
- 范围索引
- 分类索引
- 多级索引
- 间隔索引
- 日期时间索引
Day78 - 数据可视化-1
- 安装和导入matplotlib
- 创建画布
- 创建坐标系
- 绘制图表
- 折线图
- 散点图
- 柱状图
- 饼状图
- 直方图
- 箱线图
- 显示和保存图表
Day79 - 数据可视化-2
- 高阶图表
- 气泡图
- 面积图
- 雷达图
- 玫瑰图
- 3D图表
Day80 - 数据可视化-3
- Seaborn
- Pyecharts
Day81~90 - 机器学习和深度学习
Day81 - 浅谈机器学习
- 人工智能发展史
- 什么是机器学习
- 机器学习应用领域
- 机器学习的分类
- 机器学习的步骤
- 第一次机器学习
Day82 - k最近邻算法
- 距离的度量
- 数据集介绍
- kNN分类的实现
- 模型评估
- 参数调优
- kNN回归的实现
Day83 - 决策树和随机森林
- 决策树的构建
- 特征选择
- 数据分裂
- 树的剪枝
- 实现决策树模型
- 随机森林概述
Day84 - 朴素贝叶斯算法
- 贝叶斯定理
- 朴素贝叶斯
- 算法原理
- 训练阶段
- 预测阶段
- 代码实现
- 算法优缺点
Day85 - 回归模型
- 回归模型的分类
- 回归系数的计算
- 新数据集介绍
- 线性回归代码实现
- 回归模型的评估
- 引入正则化项
- 线性回归另一种实现
- 多项式回归
- 逻辑回归
Day86 - K-Means聚类算法
- 算法原理
- 数学描述
- 代码实现
Day87 - 集成学习算法
- 算法分类
- AdaBoost
- GBDT
- XGBoost
- LightGBM
Day88 - 神经网络模型
- 基本构成
- 工作原理
- 代码实现
- 模型优缺点
Day89 - 自然语言处理入门
- 词袋模型
- 词向量
- NPLM和RNN
- Seq2Seq
- Transformer
Day90 - 机器学习实战
Day91~100 - 团队项目开发
第91天:团队项目开发的问题和解决方案
-
软件过程模型
-
经典过程模型(瀑布模型)
- 可行性分析(研究做还是不做),输出《可行性分析报告》。
- 需求分析(研究做什么),输出《需求规格说明书》和产品界面原型图。
- 概要设计和详细设计,输出概念模型图(ER图)、物理模型图、类图、时序图等。
- 编码 / 测试。
- 上线 / 维护。
瀑布模型最大的缺点是无法拥抱需求变化,整套流程结束后才能看到产品,团队士气低落。
-
敏捷开发(Scrum)- 产品所有者、Scrum Master、研发人员 - Sprint
- 产品的Backlog(用户故事、产品原型)。
- 计划会议(评估和预算)。
- 日常开发(站立会议、番茄工作法、结对编程、测试先行、代码重构……)。
- 修复bug(问题描述、重现步骤、测试人员、被指派人)。
- 发布版本。
- 评审会议(Showcase,用户需要参与)。
- 回顾会议(对当前迭代周期做一个总结)。
补充:敏捷软件开发宣言
- 个体和互动 高于 流程和工具
- 工作的软件 高于 详尽的文档
- 客户合作 高于 合同谈判
- 响应变化 高于 遵循计划

角色:产品所有者(决定做什么,能对需求拍板的人)、团队负责人(解决各种问题,专注如何更好的工作,屏蔽外部对开发团队的影响)、开发团队(项目执行人员,具体指开发人员和测试人员)。
准备工作:商业案例和资金、合同、憧憬、初始产品需求、初始发布计划、入股、组建团队。
敏捷团队通常人数为8-10人。
工作量估算:将开发任务量化,包括原型、Logo设计、UI设计、前端开发等,尽量把每个工作分解到最小任务量,最小任务量标准为工作时间不能超过两天,然后估算总体项目时间。把每个任务都贴在看板上面,看板上分三部分:to do(待完成)、in progress(进行中)和done(已完成)。
-
-
项目团队组建
-
团队的构成和角色
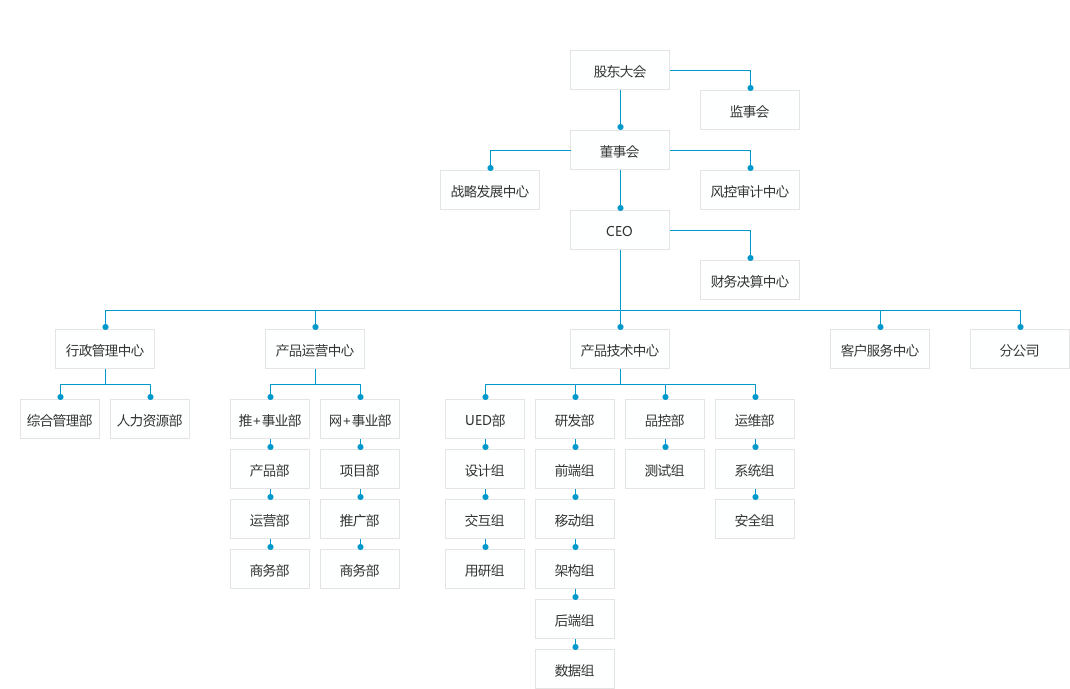
-
编程规范和代码审查(
flake8、pylint)
-
Python中的一些“惯例”(请参考《Python惯例-如何编写Pythonic的代码》)
-
影响代码可读性的原因:
- 代码注释太少或者没有注释
- 代码破坏了语言的最佳实践
- 反模式编程(意大利面代码、复制-黏贴编程、自负编程、……)
-
-
团队开发工具介绍
请参考《团队项目开发的问题和解决方案》。



-
选题范围设定
-
CMS(用户端):新闻聚合网站、问答/分享社区、影评/书评网站等。
-
MIS(用户端+管理端):KMS、KPI考核系统、HRS、CRM系统、供应链系统、仓储管理系统等。
-
App后台(管理端+数据接口):二手交易类、报刊杂志类、小众电商类、新闻资讯类、旅游类、社交类、阅读类等。
-
其他类型:自身行业背景和工作经验、业务容易理解和把控。
-
-
需求理解、模块划分和任务分配
- 需求理解:头脑风暴和竞品分析。
- 模块划分:画思维导图(XMind),每个模块是一个枝节点,每个具体的功能是一个叶节点(用动词表述),需要确保每个叶节点无法再生出新节点,确定每个叶子节点的重要性、优先级和工作量。
- 任务分配:由项目负责人根据上面的指标为每个团队成员分配任务。

-
制定项目进度表(每日更新)
模块 功能 人员 状态 完成 工时 计划开始 实际开始 计划结束 实际结束 备注 评论 添加评论 王大锤 正在进行 50% 4 2018/8/7 2018/8/7 删除评论 王大锤 等待 0% 2 2018/8/7 2018/8/7 查看评论 白元芳 正在进行 20% 4 2018/8/7 2018/8/7 需要进行代码审查 评论投票 白元芳 等待 0% 4 2018/8/8 2018/8/8 -
OOAD和数据库设计

-
UML(统一建模语言)的类图
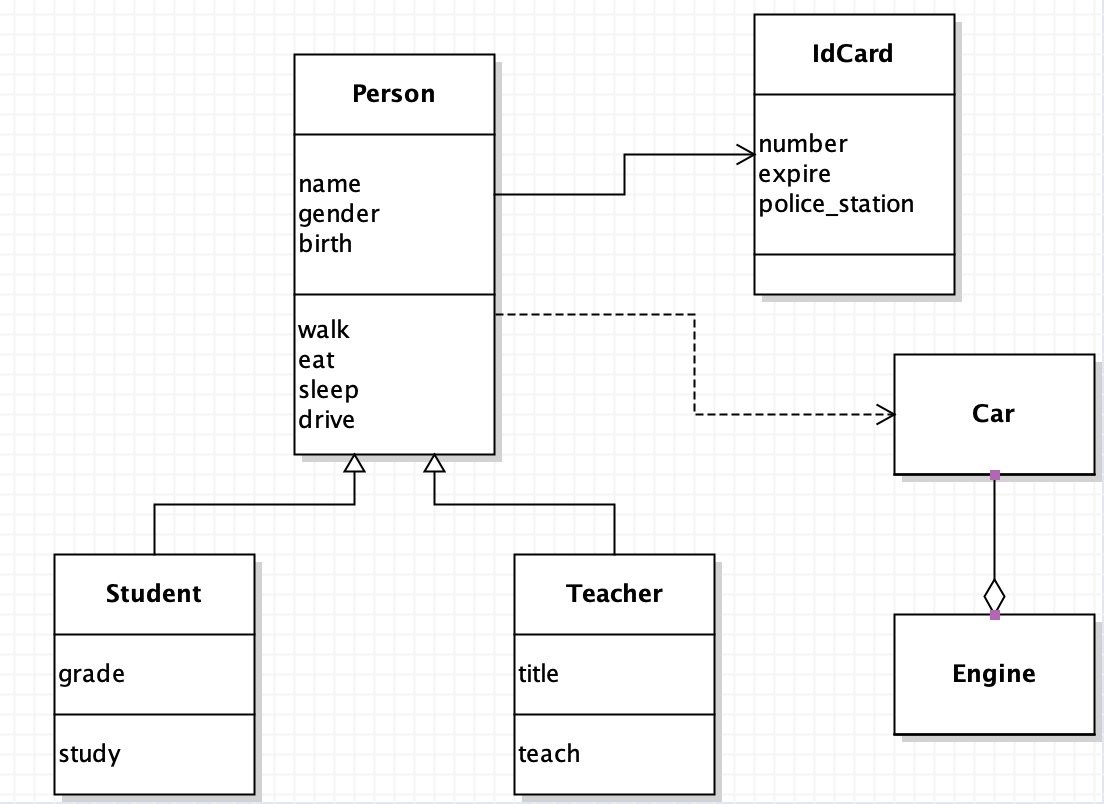
-
通过模型创建表(正向工程),例如在Django项目中可以通过下面的命令创建二维表。
python manage.py makemigrations app python manage.py migrate
-
使用PowerDesigner绘制物理模型图。

-
通过数据表创建模型(反向工程),例如在Django项目中可以通过下面的命令生成模型。
python manage.py inspectdb > app/models.py


第92天:Docker容器技术详解
- Docker简介
- 安装Docker
- 使用Docker创建容器(Nginx、MySQL、Redis、Gitlab、Jenkins)
- 构建Docker镜像(Dockerfile的编写和相关指令)
- 容器编排(Docker-compose)
- 集群管理(Kubernetes)
第93天:MySQL性能优化
- 基本原则
- InnoDB引擎
- 索引的使用和注意事项
- 数据分区
- SQL优化
- 配置优化
- 架构优化
第94天:网络API接口设计
- 设计原则
- 关键问题
- 其他问题
- 文档撰写
- 数据库的配置(多数据库、主从复制、数据库路由)
- 缓存的配置(分区缓存、键设置、超时设置、主从复制、故障恢复(哨兵))
- 日志的配置
- 分析和调试(Django-Debug-ToolBar)
- 好用的Python模块(日期计算、图像处理、数据加密、三方API)
- RESTful架构
- API接口文档的撰写
- django-REST-framework的应用
- 使用缓存缓解数据库压力 - Redis
- 使用消息队列做解耦合和削峰 - Celery + RabbitMQ
第96天:软件测试和自动化测试
- 测试的种类
- 编写单元测试(
unittest、pytest、nose2、tox、ddt、……) - 测试覆盖率(
coverage)
- 部署前的准备工作
- 关键设置(SECRET_KEY / DEBUG / ALLOWED_HOSTS / 缓存 / 数据库)
- HTTPS / CSRF_COOKIE_SECUR / SESSION_COOKIE_SECURE
- 日志相关配置
- Linux常用命令回顾
- Linux常用服务的安装和配置
- uWSGI/Gunicorn和Nginx的使用
- Gunicorn和uWSGI的比较
- 对于不需要大量定制化的简单应用程序,Gunicorn是一个不错的选择,uWSGI的学习曲线比Gunicorn要陡峭得多,Gunicorn的默认参数就已经能够适应大多数应用程序。
- uWSGI支持异构部署。
- 由于Nginx本身支持uWSGI,在线上一般都将Nginx和uWSGI捆绑在一起部署,而且uWSGI属于功能齐全且高度定制的WSGI中间件。
- 在性能上,Gunicorn和uWSGI其实表现相当。
- Gunicorn和uWSGI的比较
- 使用虚拟化技术(Docker)部署测试环境和生产环境
- AB的使用
- SQLslap的使用
- sysbench的使用
- 使用Shell和Python进行自动化测试
- 使用Selenium实现自动化测试
- Selenium IDE
- Selenium WebDriver
- Selenium Remote Control
- 测试工具Robot Framework介绍
第97天:电商网站技术要点剖析
- 商业模式和需求要点
- 物理模型设计
- 第三方登录
- 缓存预热和查询缓存
- 购物车的实现
- 支付功能集成
- 秒杀和超卖问题
- 静态资源管理
- 全文检索方案
第98天:项目部署上线和性能调优
- MySQL数据库调优
- Web服务器性能优化
- Nginx负载均衡配置
- Keepalived实现高可用
- 代码性能调优
- 多线程
- 异步化
- 静态资源访问优化
- 云存储
- CDN
第99天:面试中的公共问题
- 计算机基础
- Python基础
- Web框架相关
- 爬虫相关问题
- 数据分析
- 项目相关
第100天:补充内容
-
面试宝典
- Python 面试宝典
- 数据分析师 SQL 面试宝典
- 商业分析面试宝典
- 机器学习面试宝典
-
机器学习数学基础
-
深度学习
- 计算机视觉
- 大语言模型