Use vectorized T=byte implementations to optimize all MemoryExtensions APIs for T != byte#28080
Use vectorized T=byte implementations to optimize all MemoryExtensions APIs for T != byte#28080ahsonkhan merged 14 commits intodotnet:masterfrom
Conversation
| using nuint=System.UInt64; | ||
| #else | ||
| using nuint=System.UInt32; | ||
| using nuint = System.UInt32; |
There was a problem hiding this comment.
Nit: this formatting should be consistent with the if
| where T : IEquatable<T> | ||
| { | ||
| if (typeof(T) == typeof(byte)) | ||
| if (IsTypeNumeric<T>(out int size)) |
There was a problem hiding this comment.
With typeof(T) == typeof(byte), the JIT will avoid needing to generate any code for the other branch. Is it able to with this pattern as well? And is it then able to treat size as a const?
There was a problem hiding this comment.
Yes, the JIT is only generating the necessary code and treating size as a constant.
For byte:

For int:
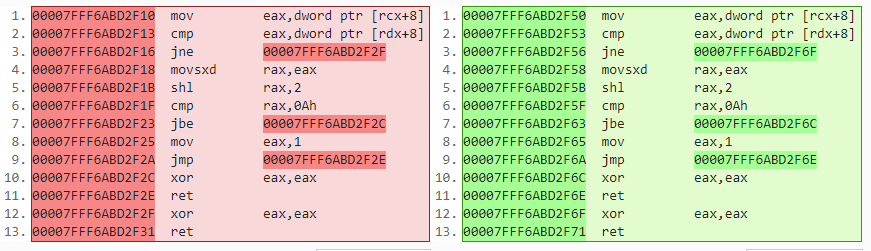
I compared the disassembly of a simplified test method:
public static bool TestB<T>(Span<T> first, ReadOnlySpan<T> second)
{
int length = first.Length;
if (IsTypeNumeric<T>(out int size))
{
return length == second.Length && SequenceEqual(((nuint)length) * (nuint)size);
}
return false;
}There was a problem hiding this comment.
What does it look before/after for Span<string> ?
There was a problem hiding this comment.
It is bad for Span<string>. Before, all checks are avoided. Now, the IsTypeNumeric method is called with all the checks.

There was a problem hiding this comment.
Is there a way to restructure the IsTypeNumeric helper method to avoid the checks for reference types like string?
cc @AndyAyersMS
There was a problem hiding this comment.
showed extra instructions even for non-reference case.
The extra instructions in the byte case earlier were a copy/paste mistake. Just like int, the byte case doesn't have overhead:

Also the real code may suffer from this more than microbechmarks. The JIT has a fixed limits on the amount of code that it optimizes or number of local variables that it optimizes. All the extra complexity counts against these limits.
I would always make the AggressiveInlining code as streamlined as possible. In this case, I think it means duplicating the code within the 6 call sites.
OK, I will duplicate the code then.
There was a problem hiding this comment.
The JIT has a fixed limits on the amount of code that it optimizes or number of local variables that it optimizes. All the extra complexity counts against these limits. I would always make the AggressiveInlining code as streamlined as possible. In this case, I think it means duplicating the code within the 6 call sites.
OK, I will duplicate the code then.
On second thought, I am not sure if this much duplication is worth it, given it would only add a few instructions specific to reference types and the code becomes long and cumbersome. If the JIT, in some cases, is unable to optimize this, then how will duplicating the code within the method help avoid that? I am not sure how we are reducing the complexity here. @jkotas, thoughts? Are there other benefits than having one less method that is marked with AggressiveInlining?
There was a problem hiding this comment.
If you inline the code manually, the JIT turns a lot of things into constants right away. The dead code can be pruned quickly, and the trees created are generally simple. If you let the JIT to do the inlining, there are complex trees created first and that the JIT needs to work hard to simplify. It has likely negative impact on both JIT throughput; and on the code quality. I think you should be able to see the impact on code quality if you manually unroll the microbenchmark to calls these methods say 50x. This should be enough to hit the JITs thresholds on too complex code. Measure the performance with both with and without manual inlining.
@AndyAyersMS Do you have an opinion whether it is better to inline manually or whether it is better to have the nested aggressively inlined methods here?
There was a problem hiding this comment.
I think you should be able to see the impact on code quality if you manually unroll the microbenchmark to calls these methods say 50x. This should be enough to hit the JITs thresholds on too complex code. Measure the performance with both with and without manual inlining.
I call the method ~50x times (result &= StartsWith(...)) within each iteration of the benchmark. I wasn't able to see a performance difference:


It is a tough call to make without seeing impact in larger programs. But even then, we may need some heavy use of these APIs to see any difference.
There was a problem hiding this comment.
The jit has gotten better at early (importer) pruning of dead code so often times we only import a slice of a method. We're also more aggressive about forwarding values into inline bodies and out of returns.
So I think the nested aggressive inline is ok here from the jit's standpoint, and it probably makes the code more readable/maintainable.
| { | ||
| Debug.Assert(0 <= index && index <= searchSpaceLength); // Ensures no deceptive underflows in the computation of "remainingSearchSpaceLength". | ||
| int remainingSearchSpaceLength = searchSpaceLength - index - valueTailLength; | ||
| Debug.Assert(0 <= index && searchSpaceLength >= index); // Ensures no deceptive underflows in the computation of "remainingSearchSpaceLength". |
There was a problem hiding this comment.
I added the >=(NUInt left, int right) operator, but not the other way around (i.e. <=(int left, NUInt right)) to the NUint wrapper for netfx.
There was a problem hiding this comment.
I think we should add as many operators as necessary to NUInt. so we do not need unnatural workarounds like this.
There was a problem hiding this comment.
OK. I will go ahead and add the necessary combinations.
| ref Unsafe.As<T, byte>(ref MemoryMarshal.GetReference(span)), | ||
| Unsafe.As<T, byte>(ref value), | ||
| span.Length); | ||
| ((nuint)span.Length) * size); |
There was a problem hiding this comment.
If I am reading this correctly, this is going to return byte index now. Doesn't it need to return the actual item index?
A lot of tests should be failing because of this.
There was a problem hiding this comment.
Yes, and they are. Fixing it now.
| uint uValue2 = value2; // Use uint for comparisons to avoid unnecessary 8->32 extensions | ||
| IntPtr index = (IntPtr)0; // Use UIntPtr for arithmetic to avoid unnecessary 64->32->64 truncations | ||
| IntPtr nLength = (IntPtr)(uint)length; | ||
| IntPtr nLength = (IntPtr)length; |
There was a problem hiding this comment.
We should use nuint instead of IntPtr in the implementation instead of the hacky combination of IntPtrs and pointers.
| var minLength = firstLength; | ||
| if (minLength > secondLength) minLength = secondLength; | ||
| nuint minLength = firstLength; | ||
| if ((byte*)(IntPtr)minLength > (byte*)(IntPtr)secondLength) minLength = secondLength; |
There was a problem hiding this comment.
This can be just:
if (minLength > secondLength) minLength = secondLength;
| goto Equal; | ||
|
|
||
| var minLength = firstLength; | ||
| nuint minLength = firstLength; |
There was a problem hiding this comment.
SequenceEqual has almost identical code, can use the same cleanup.
|
I think if you add in the |
| } | ||
|
|
||
| [MethodImpl(MethodImplOptions.AggressiveInlining)] | ||
| private static bool IsTypeNumeric<T>(out int size) |
There was a problem hiding this comment.
A better name would be something like IsComparableAsBytes. IsTypeNumeric sounds like it should include types like R4 and R8 and Decimal (which it shouldn't - you can't use byte compare to compare those types) Also, char isn't really "numeric."
You could also test for IntPtr/UIntPtr here.
There was a problem hiding this comment.
Might be better just to have to return a nuint size. You're casting it to nuint everywhere you use it anyway.
| return true; | ||
| } | ||
|
|
||
| size = 0; |
There was a problem hiding this comment.
Nit: prefer size = default; here as the intent isn't that the size is zero, the intent is that the size is uninteresting.
| [MethodImpl(MethodImplOptions.AggressiveInlining)] | ||
| public static NUInt operator *(NUInt left, NUInt right) | ||
| { | ||
| unsafe { return (sizeof(IntPtr) == 4) ? new NUInt(((uint)left._value) * (uint)right._value) : new NUInt(((ulong)left._value) * (uint)right._value); } |
There was a problem hiding this comment.
The rightmost cast of right to uint will cause value loss. Same with other operators that take a NUint right
| public static int SequenceCompareTo<T>(this Span<T> first, ReadOnlySpan<T> second) | ||
| where T : IComparable<T> | ||
| { | ||
| if (typeof(T) == typeof(byte)) |
There was a problem hiding this comment.
I don't think you can validly apply this optimization to SequentialCompare - comparing unsigned bytes one at a time isn't the same as comparing elements using the proper Compare algorithm.
There was a problem hiding this comment.
Good point. I will revert this. We need to add more tests for T != byte for SequenceCompareTo.
There was a problem hiding this comment.
|
Sample performance impact (chose StartsWith): |

|
The regressions for small value sizes are not good. I would expect that StartsWith will be typically used with small value sizes. |
The regression is only there for length == 1. I want to run some tests and collect data, and if that case is very common, we can consider special casing it.
|

|
Ok, this looks better. |
|
@dotnet-bot test OSX x64 Debug Build Filed https://github.com/dotnet/corefx/issues/28133 |
|
@ahsonkhan Mirror was blocked but now its up again. mirror has already opened PRs. This will be picked after the opened PRs has been merged |
…s APIs for T != byte (dotnet#28080) * Adding IsTypeNumeric helper * Add more NUint operations and use IsTypeNumeric everywhere. * Revert addition of LangVersion 7.2 * Fix formatting * Revert use of nuint and IsNumericType for *IndexOf* APIs * Fix comment, undo leftover changes, and fix indentation. * Address PR feedback - use nuint where possible. * PR feedback - Cleanup SequenceEqual just like SequenceCompareTo * Add new NUInt operations for netcoreapp/coreclr mirror. * Address PR feedback * Add T = char and T = long tests for StartsWith and EndsWith
…s APIs for T != byte (dotnet/corefx#28080) * Adding IsTypeNumeric helper * Add more NUint operations and use IsTypeNumeric everywhere. * Revert addition of LangVersion 7.2 * Fix formatting * Revert use of nuint and IsNumericType for *IndexOf* APIs * Fix comment, undo leftover changes, and fix indentation. * Address PR feedback - use nuint where possible. * PR feedback - Cleanup SequenceEqual just like SequenceCompareTo * Add new NUInt operations for netcoreapp/coreclr mirror. * Address PR feedback * Add T = char and T = long tests for StartsWith and EndsWith Commit migrated from dotnet/corefx@6cc11f5
Related to https://github.com/dotnet/corefx/issues/27487 and partially addresses https://github.com/dotnet/corefx/issues/27379
Builds on top of #27859 / #28073
TODO:
Add more unit tests andmeasure performance impactcc @atsushikan, @jkotas, @stephentoub, @KrzysztofCwalina