Rate Limiting Algorithms are mechanisms designed to control the rate at which requests are processed or served by a system. These algorithms are crucial in various domains such as web services, APIs, network traffic management, and distributed systems to ensure stability, fairness, and protection against abuse.
- Prevents system overload by limiting excessive requests
- Ensures fair usage among users and avoids abuse
Example: An API allows only 100 requests per minute per user; if exceeded, further requests are temporarily blocked.
1. Token Bucket Algorithm
The token bucket algorithm controls data flow by generating tokens at a steady rate, which are required to process requests. If tokens are available, requests are allowed; otherwise, they are denied. It helps manage varying traffic while maintaining a defined rate limit.
- Allows bursts of traffic while still enforcing an overall rate limit.
- Rejects or delays requests when tokens are not available.
Example: Video streaming service where data is sent in bursts when enough tokens are available.

Benefits
Highlights the advantages of the token bucket algorithm in handling traffic efficiently.
- Easy to understand and not difficult to put into practice.
- Enables its links to handle burst traffic.
- Allows rate liming to be flexible in its approach.
Challenges
Describes the limitations and considerations when using the token bucket algorithm.
- Demands a high level of coordination in the rate of token building.
- May work in a busy setting but may require some adjustments for a slow paced setting.
Working
Explains how the token bucket algorithm operates step-by-step.
- Token bucket can be easily implemented with a counter.
- The token is initiated to zero.
- Each time a token is added, counter is incremented to 1.
- Each time a unit of data is sent, counter is decremented by 1.
- When the counter is zero, host cannot send data.
Implementation
class TokenBucket:
def __init__(self, rate, capacity):
self.rate = rate
self.capacity = capacity
self.tokens = capacity
self.last_refill = time.time()
def allow_request(self):
now = time.time()
self.tokens += (now - self.last_refill) * self.rate
self.tokens = min(self.tokens, self.capacity)
self.last_refill = now
if self.tokens >= 1:
self.tokens -= 1
return True
else:
return False
2. Leaky Bucket Algorithm
The leaky bucket approach controls request flow by processing data at a constant rate while storing incoming requests in a fixed-size bucket. If the bucket becomes full, additional requests are rejected. It ensures a steady and predictable output rate.
- Maintains a constant processing rate regardless of incoming traffic
- Drops excess requests when the bucket capacity is exceeded
Example: API rate limiting where requests are handled at a steady rate

Benefits
Shows how this approach helps manage traffic in a controlled and efficient way.
- Smooths out bursty traffic by enforcing a steady output rate.
- Ensures fair distribution of resources among users or applications.
- Relatively easy to implement and understand.
- Helps mitigate certain types of Denial of Service (DoS) attacks.
Challenges
Outlines the trade-offs and potential limitations in real-world usage.
- Requires additional computational overhead to manage tokens.
- May struggle to handle very short-lived bursts that exceed the bucket's capacity.
- Strictly enforces rate limits, which can affect applications needing occasional bursts.
- Choosing optimal bucket size and refill rate can be complex.
Working
Describes the step-by-step flow of how data is regulated through the system.
- Imagine a bucket that has a leak at the bottom.
- Data (or tokens) arrive at the bucket at irregular intervals.
- Each unit of data that arrives is held in the bucket until it can be processed.
- Data is removed from the bucket at a constant rate determined by the leak rate.
- If the bucket fills up and overflows, excess data is discarded or delayed.
Implementation
class LeakyBucket:
def __init__(self, capacity, leak_rate):
self.capacity = capacity # Maximum capacity of the bucket
self.leak_rate = leak_rate # Rate at which the bucket leaks (units per second)
self.bucket_size = 0 # Current size of the bucket
self.last_updated = time.time() # Last time the bucket was updated
def add_data(self, data_size):
# Calculate time elapsed since last update
current_time = time.time()
time_elapsed = current_time - self.last_updated
self.last_updated = current_time
# Leak the bucket (remove data according to the leak rate)
self.bucket_size -= self.leak_rate * time_elapsed
# Add new data to the bucket
self.bucket_size = min(self.bucket_size + data_size, self.capacity)
# Check if data can be sent
if self.bucket_size >= data_size:
self.bucket_size -= data_size
return True
else:
return False
# Example usage:
bucket = LeakyBucket(capacity=10, leak_rate=1) # Bucket with capacity of 10 units and leak rate of 1 unit per second
data_to_send = 5 # Example data size to send
if bucket.add_data(data_to_send):
print(f"Data of size {data_to_send} sent successfully.")
else:
print(f"Bucket overflow. Unable to send data of size {data_to_send}.")
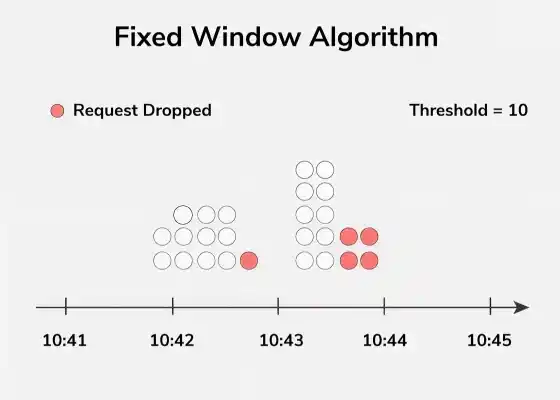
3. Fixed Window Algorithm
The fixed window algorithm divides time into equal intervals and limits the number of requests within each window. If the limit is exceeded, further requests are blocked until the next window begins. It is simple but can allow bursts at window boundaries.
- Easy to implement and works well for steady traffic.
- Can cause sudden spikes at the start of a new window.
Example: A login system allows 5 attempts per minute; if exceeded, further attempts are blocked until the next minute starts.
Benefits
Highlights why this approach is useful for basic rate limiting scenarios.
- Simple to implement.
- Good for stable flow of traffic.
Challenges
Explains the limitations when dealing with dynamic traffic patterns.
- Can lead to bursts at the boundary of windows.
- Although very well suited for static traffic they are not suitable very much when it comes to variable traffic patterns.
Working
Describes how requests are counted and controlled over fixed intervals.
- The fixed window counting algorithm tracks the number of requests within a fixed time window (e.g., one minute, one hour).
- Requests exceeding a predefined threshold within the window are rejected or delayed until the window resets.
Implementation
class FixedWindow:
def __init__(self, window_size, max_requests):
self.window_size = window_size
self.max_requests = max_requests
self.requests = 0
self.window_start = time.time()
def allow_request(self):
now = time.time()
if now - self.window_start >= self.window_size:
self.requests = 0
self.window_start = now
if self.requests < self.max_requests:
self.requests += 1
return True
else:
return False
4. Sliding Window Algorithm
The sliding window algorithm uses a continuously moving time frame to limit the number of requests. It combines advantages of fixed window and leaky bucket, providing smoother and more accurate rate control. This helps distribute requests evenly over time.
- Provides better accuracy and smoother traffic control.
- Handles bursty and variable traffic more effectively.
Example: A messaging system allows 20 messages in any rolling 1-minute window, instead of resetting the count every fixed minute.

Benefits
Explains why this method is preferred for handling dynamic traffic scenarios.
- It is less precise than a fixed window, but more flexible as well and therefore often recommended.
- Handles with Variable traffic pattern in a better way.
Challenges
Highlights the added complexity and resource requirements.
- Somewhat more complicated to perform.
- More complex and requires more memory and computation than the other categories.
Working
Describes how requests are tracked over a continuously moving time window.
- The sliding window log algorithm maintains a log of timestamps for each request received.
- Requests older than a predefined time interval are removed from the log, and new requests are added.
- The rate of requests is calculated based on the number of requests within the sliding window.
Implementation
class SlidingWindow:
def __init__(self, window_size, max_requests):
self.window_size = window_size
self.max_requests = max_requests
self.requests = deque()
def allow_request(self):
now = time.time()
while self.requests and self.requests[0] <= now - self.window_size:
self.requests.popleft()
if len(self.requests) < self.max_requests:
self.requests.append(now)
return True
else:
return False
Selecting the Best Rate Limiting Strategy
Choosing the right rate limiting algorithm depends on several factors:
Traffic Pattern
Helps understand how traffic behaves in the system.
- Determine whether traffic is bursty or constant to handle spikes or steady flow.
- Analyze peak time, average rate, and fluctuations to choose the right algorithm.
Implementation Complexity
Defines how easy or difficult the algorithm is to implement.
- Simpler algorithms like fixed window are easy but less flexible.
- Complex ones like sliding window or token bucket offer better control but need more effort.
Performance Requirements
Ensures the system meets performance and latency needs.
- Choose algorithms that meet system performance and latency requirements.
- Prefer low-overhead algorithms for high-performance systems.
Scalability
Focuses on handling increasing traffic and users.
- The algorithm should handle growth in traffic efficiently.
- It should remain effective as the system scales over time.
Flexibility
Allows adaptation to changing traffic conditions.
- Choose algorithms that can adjust based on traffic patterns.
- Helps balance strict rate limiting with occasional bursts.
Handling Bursts and Spikes
Handling bursts and spikes efficiently is crucial for maintaining system stability:
- Token Bucket: Ideal for dealing with bursts as it stores the tokens. This helps in dealing with high traffic bursts in the quickest way possible without necessarily resulting in an immediate rejection.
- Leaky Bucket: Tames bursts by handling the flow in a manner that is even though requests may come in bursts.
- Sliding Window: Has the ability to take care of fluctuating traffic by fixing the window and provides a better rate control by varying the window.
- Hybrid Approaches: Use techniques in parallel and supplement each other, for example, token bucket with the fixed window. This hybrid approach therefore prove to be efficient in the management of steady and burst traffics.
Real-World Examples
Below are some real-world examples where rate limiting can be used:
- APIs: To avoid various abuses, most APIs, including Tweeter, GitHub, and Google Maps, reduce the rage of the requests that may be made in a given interval of time.
- Web Servers: Rate limiting is used in Web servers to mitigate DoS attack and control the resources usage of a server when the traffic density is high or low to maintain the server’s availability.
- Content Delivery Networks (CDNs): CDNs impose rate limits on the access against cached objects to avoid various types of congestions, to provide a steady delivery of the content to users from various geographical locations.
- E-commerce Platforms: That is why rate limiting is implemented on e-commerce sites to necessary regulate traffic during the sales, protect against bots taking over the site and limit the possibility of some customers making multiple purchases while others cannot buy anything at all