Multi-Layer Perceptron Learning in Tensorflow
Last Updated :
25 May, 2025
Multi-Layer Perceptron (MLP) consists of fully connected dense layers that transform input data from one dimension to another. It is called multi-layer because it contains an input layer, one or more hidden layers and an output layer. The purpose of an MLP is to model complex relationships between inputs and outputs.
Components of Multi-Layer Perceptron (MLP)
- Input Layer: Each neuron or node in this layer corresponds to an input feature. For instance, if you have three input features the input layer will have three neurons.
- Hidden Layers: MLP can have any number of hidden layers with each layer containing any number of nodes. These layers process the information received from the input layer.
- Output Layer: The output layer generates the final prediction or result. If there are multiple outputs, the output layer will have a corresponding number of neurons.
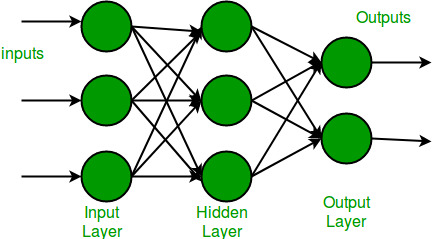
Every connection in the diagram is a representation of the fully connected nature of an MLP. This means that every node in one layer connects to every node in the next layer. As the data moves through the network each layer transforms it until the final output is generated in the output layer.
Working of Multi-Layer Perceptron
Let's see working of the multi-layer perceptron. The key mechanisms such as forward propagation, loss function, backpropagation and optimization.
1. Forward Propagation
In forward propagation the data flows from the input layer to the output layer, passing through any hidden layers. Each neuron in the hidden layers processes the input as follows:
1. Weighted Sum: The neuron computes the weighted sum of the inputs:
z = \sum_{i} w_i x_i + b
Where:
- x_i is the input feature.
- w_i is the corresponding weight.
- b is the bias term.
2. Activation Function: The weighted sum z is passed through an activation function to introduce non-linearity. Common activation functions include:
- Sigmoid: \sigma(z) = \frac{1}{1 + e^{-z}}
- ReLU (Rectified Linear Unit): f(z) = \max(0, z)
- Tanh (Hyperbolic Tangent): \tanh(z) = \frac{2}{1 + e^{-2z}} - 1
2. Loss Function
Once the network generates an output the next step is to calculate the loss using a loss function. In supervised learning this compares the predicted output to the actual label.
For a classification problem the commonly used binary cross-entropy loss function is:
L = -\frac{1}{N} \sum_{i=1}^{N} \left[ y_i \log(\hat{y}_i) + (1 - y_i) \log(1 - \hat{y}_i) \right]
Where:
- y_i is the actual label.
- \hat{y}_i is the predicted label.
- N is the number of samples.
For regression problems the mean squared error (MSE) is often used:
MSE = \frac{1}{N} \sum_{i=1}^{N} (y_i - \hat{y}_i)^2
3. Backpropagation
The goal of training an MLP is to minimize the loss function by adjusting the network's weights and biases. This is achieved through backpropagation:
- Gradient Calculation: The gradients of the loss function with respect to each weight and bias are calculated using the chain rule of calculus.
- Error Propagation: The error is propagated back through the network, layer by layer.
- Gradient Descent: The network updates the weights and biases by moving in the opposite direction of the gradient to reduce the loss: w = w - \eta \cdot \frac{\partial L}{\partial w}
Where:
- w is the weight.
- \eta is the learning rate.
- \frac{\partial L}{\partial w} is the gradient of the loss function with respect to the weight.
4. Optimization
MLPs rely on optimization algorithms to iteratively refine the weights and biases during training. Popular optimization methods include:
- Stochastic Gradient Descent (SGD): Updates the weights based on a single sample or a small batch of data: w = w - \eta \cdot \frac{\partial L}{\partial w}
- Adam Optimizer: An extension of SGD that incorporates momentum and adaptive learning rates for more efficient training:
- m_t = \beta_1 m_{t-1} + (1 - \beta_1) \cdot g_t
- v_t = \beta_2 v_{t-1} + (1 - \beta_2) \cdot g_t^2
- Here g_t represents the gradient at time t and \beta_1, \beta_2 are decay rates.
Now that we are done with the theory part of multi-layer perception, let's go ahead and implement code in python using the TensorFlow library.
Implementing Multi Layer Perceptron
In this section, we will guide through building a neural network using TensorFlow.
1. Importing Modules and Loading Dataset
First we import necessary libraries such as TensorFlow, NumPy and Matplotlib for visualizing the data. We also load the MNIST dataset.
Python
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
2. Loading and Normalizing Image Data
Next we normalize the image data by dividing by 255 (since pixel values range from 0 to 255) which helps in faster convergence during training.
Python
gray_scale = 255
x_train = x_train.astype('float32') / gray_scale
x_test = x_test.astype('float32') / gray_scale
print("Feature matrix (x_train):", x_train.shape)
print("Target matrix (y_train):", y_train.shape)
print("Feature matrix (x_test):", x_test.shape)
print("Target matrix (y_test):", y_test.shape)
Output:
 Multi-Layer Perceptron Learning in Tensorflow
Multi-Layer Perceptron Learning in Tensorflow3. Visualizing Data
To understand the data better we plot the first 100 training samples each representing a digit.
Python
fig, ax = plt.subplots(10, 10)
k = 0
for i in range(10):
for j in range(10):
ax[i][j].imshow(x_train[k].reshape(28, 28), aspect='auto')
k += 1
plt.show()
Output:
 Multi-Layer Perceptron Learning in Tensorflow
Multi-Layer Perceptron Learning in Tensorflow4. Building the Neural Network Model
Here we build a Sequential neural network model. The model consists of:
- Flatten Layer: Reshapes 2D input (28x28 pixels) into a 1D array of 784 elements.
- Dense Layers: Fully connected layers with 256 and 128 neurons, both using the relu activation function.
- Output Layer: The final layer with 10 neurons representing the 10 classes of digits (0-9) with sigmoid activation.
Python
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(256, activation='sigmoid'),
Dense(128, activation='sigmoid'),
Dense(10, activation='softmax'),
])
5. Compiling the Model
Once the model is defined we compile it by specifying:
- Optimizer: Adam for efficient weight updates.
- Loss Function: Sparse categorical cross entropy, which is suitable for multi-class classification.
- Metrics: Accuracy to evaluate model performance.
Python
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
6. Training the Model
We train the model on the training data using 10 epochs and a batch size of 2000. We also use 20% of the training data for validation to monitor the model’s performance on unseen data during training.
Python
mod = model.fit(x_train, y_train, epochs=10,
batch_size=2000,
validation_split=0.2)
print(mod)
Output:
 Multi-Layer Perceptron Learning in Tensorflow
Multi-Layer Perceptron Learning in Tensorflow7. Evaluating the Model
After training we evaluate the model on the test dataset to determine its performance.
Python
results = model.evaluate(x_test, y_test, verbose=0)
print('Test loss, Test accuracy:', results)
Output:
Test loss, Test accuracy: [0.2682029604911804, 0.9257000088691711]
We got the accuracy of our model 92% by using model.evaluate() on the test samples.
8. Visualizing Training and Validation Loss VS Accuracy
Python
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(mod.history['accuracy'], label='Training Accuracy', color='blue')
plt.plot(mod.history['val_accuracy'], label='Validation Accuracy', color='orange')
plt.title('Training and Validation Accuracy', fontsize=14)
plt.xlabel('Epochs', fontsize=12)
plt.ylabel('Accuracy', fontsize=12)
plt.legend()
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(mod.history['loss'], label='Training Loss', color='blue')
plt.plot(mod.history['val_loss'], label='Validation Loss', color='orange')
plt.title('Training and Validation Loss', fontsize=14)
plt.xlabel('Epochs', fontsize=12)
plt.ylabel('Loss', fontsize=12)
plt.legend()
plt.grid(True)
plt.suptitle("Model Training Performance", fontsize=16)
plt.tight_layout()
plt.show()
Output:
 Multi-Layer Perceptron Learning in Tensorflow
Multi-Layer Perceptron Learning in TensorflowThe model is learning effectively on the training set, but the validation accuracy and loss levels off which might indicate that the model is starting to overfit.
Advantages of Multi Layer Perceptron
- Versatility: MLPs can be applied to a variety of problems, both classification and regression.
- Non-linearity: Using activation functions MLPs can model complex, non-linear relationships in data.
- Parallel Computation: With the help of GPUs, MLPs can be trained quickly by taking advantage of parallel computing.
Disadvantages of Multi Layer Perceptron
- Computationally Expensive: MLPs can be slow to train especially on large datasets with many layers.
- Prone to Overfitting: Without proper regularization techniques they can overfit the training data, leading to poor generalization.
- Sensitivity to Data Scaling: They require properly normalized or scaled data for optimal performance.
In short Multilayer Perceptron has the ability to learn complex patterns from data makes it a valuable tool in machine learning.
Similar Reads
Deep Learning Tutorial
Deep Learning tutorial covers the basics and more advanced topics, making it perfect for beginners and those with experience. Whether you're just starting or looking to expand your knowledge, this guide makes it easy to learn about the different technologies of Deep Learning.Deep Learning is a branc
5 min read
Introduction to Deep Learning
Artificial Neural Network
Introduction to Convolution Neural Network
Introduction to Convolution Neural Network
Convolutional Neural Network (CNN) is an advanced version of artificial neural networks (ANNs), primarily designed to extract features from grid-like matrix datasets. This is particularly useful for visual datasets such as images or videos, where data patterns play a crucial role. CNNs are widely us
8 min read
Digital Image Processing Basics
Digital Image Processing means processing digital image by means of a digital computer. We can also say that it is a use of computer algorithms, in order to get enhanced image either to extract some useful information. Digital image processing is the use of algorithms and mathematical models to proc
7 min read
Difference between Image Processing and Computer Vision
Image processing and Computer Vision both are very exciting field of Computer Science. Computer Vision: In Computer Vision, computers or machines are made to gain high-level understanding from the input digital images or videos with the purpose of automating tasks that the human visual system can do
2 min read
CNN | Introduction to Pooling Layer
Pooling layer is used in CNNs to reduce the spatial dimensions (width and height) of the input feature maps while retaining the most important information. It involves sliding a two-dimensional filter over each channel of a feature map and summarizing the features within the region covered by the fi
5 min read
CIFAR-10 Image Classification in TensorFlow
Prerequisites:Image ClassificationConvolution Neural Networks including basic pooling, convolution layers with normalization in neural networks, and dropout.Data Augmentation.Neural Networks.Numpy arrays.In this article, we are going to discuss how to classify images using TensorFlow. Image Classifi
8 min read
Implementation of a CNN based Image Classifier using PyTorch
Introduction: Introduced in the 1980s by Yann LeCun, Convolution Neural Networks(also called CNNs or ConvNets) have come a long way. From being employed for simple digit classification tasks, CNN-based architectures are being used very profoundly over much Deep Learning and Computer Vision-related t
9 min read
Convolutional Neural Network (CNN) Architectures
Convolutional Neural Network(CNN) is a neural network architecture in Deep Learning, used to recognize the pattern from structured arrays. However, over many years, CNN architectures have evolved. Many variants of the fundamental CNN Architecture This been developed, leading to amazing advances in t
11 min read
Object Detection vs Object Recognition vs Image Segmentation
Object Recognition: Object recognition is the technique of identifying the object present in images and videos. It is one of the most important applications of machine learning and deep learning. The goal of this field is to teach machines to understand (recognize) the content of an image just like
5 min read
YOLO v2 - Object Detection
In terms of speed, YOLO is one of the best models in object recognition, able to recognize objects and process frames at the rate up to 150 FPS for small networks. However, In terms of accuracy mAP, YOLO was not the state of the art model but has fairly good Mean average Precision (mAP) of 63% when
7 min read
Recurrent Neural Network
Natural Language Processing (NLP) Tutorial
Natural Language Processing (NLP) is the branch of Artificial Intelligence (AI) that gives the ability to machine understand and process human languages. Human languages can be in the form of text or audio format.Applications of NLPThe applications of Natural Language Processing are as follows:Voice
5 min read
Introduction to NLTK: Tokenization, Stemming, Lemmatization, POS Tagging
Natural Language Toolkit (NLTK) is one of the largest Python libraries for performing various Natural Language Processing tasks. From rudimentary tasks such as text pre-processing to tasks like vectorized representation of text - NLTK's API has covered everything. In this article, we will accustom o
5 min read
Word Embeddings in NLP
Word Embeddings are numeric representations of words in a lower-dimensional space, that capture semantic and syntactic information. They play a important role in Natural Language Processing (NLP) tasks. Here, we'll discuss some traditional and neural approaches used to implement Word Embeddings, suc
14 min read
Introduction to Recurrent Neural Networks
Recurrent Neural Networks (RNNs) differ from regular neural networks in how they process information. While standard neural networks pass information in one direction i.e from input to output, RNNs feed information back into the network at each step.Imagine reading a sentence and you try to predict
10 min read
Recurrent Neural Networks Explanation
Today, different Machine Learning techniques are used to handle different types of data. One of the most difficult types of data to handle and the forecast is sequential data. Sequential data is different from other types of data in the sense that while all the features of a typical dataset can be a
8 min read
Sentiment Analysis with an Recurrent Neural Networks (RNN)
Recurrent Neural Networks (RNNs) are used in sequence tasks such as sentiment analysis due to their ability to capture context from sequential data. In this article we will be apply RNNs to analyze the sentiment of customer reviews from Swiggy food delivery platform. The goal is to classify reviews
5 min read
Short term Memory
In the wider community of neurologists and those who are researching the brain, It is agreed that two temporarily distinct processes contribute to the acquisition and expression of brain functions. These variations can result in long-lasting alterations in neuron operations, for instance through act
5 min read
What is LSTM - Long Short Term Memory?
Long Short-Term Memory (LSTM) is an enhanced version of the Recurrent Neural Network (RNN) designed by Hochreiter and Schmidhuber. LSTMs can capture long-term dependencies in sequential data making them ideal for tasks like language translation, speech recognition and time series forecasting. Unlike
5 min read
Long Short Term Memory Networks Explanation
Prerequisites: Recurrent Neural Networks To solve the problem of Vanishing and Exploding Gradients in a Deep Recurrent Neural Network, many variations were developed. One of the most famous of them is the Long Short Term Memory Network(LSTM). In concept, an LSTM recurrent unit tries to "remember" al
7 min read
LSTM - Derivation of Back propagation through time
Long Short-Term Memory (LSTM) are a type of neural network designed to handle long-term dependencies by handling the vanishing gradient problem. One of the fundamental techniques used to train LSTMs is Backpropagation Through Time (BPTT) where we have sequential data. In this article we see how BPTT
4 min read
Text Generation using Recurrent Long Short Term Memory Network
LSTMs are a type of neural network that are well-suited for tasks involving sequential data such as text generation. They are particularly useful because they can remember long-term dependencies in the data which is crucial when dealing with text that often has context that spans over multiple words
4 min read