Monte Carlo integration is a statistical technique that uses random sampling to estimate definite integrals, making it ideal for complex or high-dimensional cases where traditional methods fall short. With Python, we can implement and parallelize this technique for fast, flexible numerical integration.
The goal is to estimate a definite integral:
Instead of evaluating f(x) at every point, we draw
I \approx (b - a) \frac{1}{N} \sum_{i=1}^N f(x_i)
Due to the law of large numbers, this approximation improves as
Implementing Monte Carlo integration
Now lets see its implement it using python:
1. Required Python Libraries
- NumPy: For fast numeric operations and random number generation.
- Matplotlib: For plotting and visualizations.p.
!pip install numpy matplotlib
2. Monte Carlo Integration Example
We will estimate:
import numpy as np
a, b, N = 0, np.pi, 1000
def f(x):
return np.sin(x)
x_random = np.random.uniform(a, b, N)
estimate = (b - a) * np.mean(f(x_random))
print(f"Monte Carlo Estimate: {estimate:.4f}")
Output:
Monte Carlo Estimate: 2.0067
3. Visualizing Result
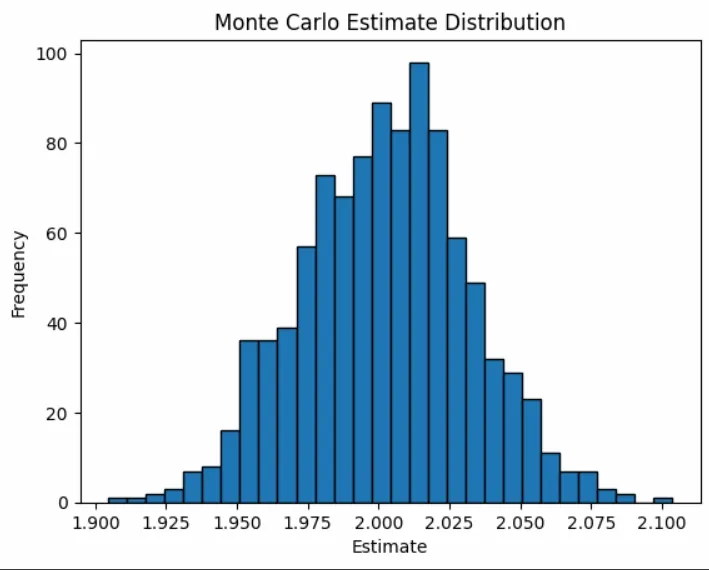
Monte Carlo estimates are statistical i.e they fluctuate. We can visualize this variability by repeating the procedure many times and plotting the results:
import matplotlib.pyplot as plt
repeats = 1000
estimates = []
for _ in range(repeats):
x_samples = np.random.uniform(a, b, N)
estimates.append((b - a) * np.mean(f(x_samples)))
plt.hist(estimates, bins=30, edgecolor='black')
plt.title("Monte Carlo Estimate Distribution")
plt.xlabel("Estimate")
plt.ylabel("Frequency")
plt.show()
4. Distributed/Parallel Monte Carlo Integration
To further speed up calculations, Monte Carlo integration adapts easily to parallel computing. Each batch of random samples can be processed independently.
- Makes full use of all CPU cores.
- Greatly reduces computation time for large N or repeated estimates.
import numpy as np
from multiprocessing import Pool, cpu_count
def monte_carlo_worker(args):
a, b, N, f = args
x_rand = np.random.uniform(a, b, N)
return (b - a) * np.mean(f(x_rand))
a, b, N_per_cpu = 0, np.pi, 10_000
repeats = 100
func = np.sin
num_workers = cpu_count()
with Pool(num_workers) as pool:
tasks = [(a, b, N_per_cpu, func) for _ in range(repeats)]
parallel_results = pool.map(monte_carlo_worker, tasks)
print(f"Mean Estimate (parallel): {np.mean(parallel_results):.4f}")
Output:
Mean Estimate (parallel): 2.0016
5. Sample Example
Here we will Integrate
a, b, N = 0, 1, 1000
def f(x):
return x**2
x_random = np.random.uniform(a, b, N)
estimate = (b - a) * np.mean(f(x_random))
print(f"Monte Carlo Estimate: {estimate:.4f}")
Output:
Monte Carlo Estimate: 0.3137
Monte Carlo integration in Python provides a robust and versatile framework for tackling complex or high-dimensional integrals where traditional analytical or numerical methods may be impractical. Its flexibility allows seamless adaptation to a wide range of problems across science, engineering and data analysis.