Design Web Crawler | System Design
Last Updated :
15 May, 2024
Creating a web crawler system requires careful planning to make sure it collects and uses web content effectively while being able to handle large amounts of data. We'll explore the main parts and design choices of such a system in this article.

Important Topics for Web Crawler System Design
- URL Discovery: Implement mechanisms to discover and enqueue URLs from various sources like sitemaps, seed URLs, and discovered links.
- Content Extraction: Extract relevant information from fetched pages, including text content, links, metadata, and structured data.
- Prioritization: Prioritize pages based on factors such as relevance, importance, and freshness to optimize crawling efficiency.
- Handling Content Types: Support parsing and handling of various content types like HTML, CSS, JavaScript, images, and documents.
- Scalability: Design the system to scale horizontally to handle a growing volume of web pages and concurrent requests.
- Performance: Ensure efficient fetching and processing of web pages to minimize latency and maximize throughput.
- Robustness: Handle errors, timeouts, and diverse scenarios gracefully to maintain system stability and reliability.
- Maintainability: Organize the codebase into modular components for ease of maintenance and future enhancements.
- Security: Implement measures to protect against malicious content and ensure the security of crawled data.
Capacity Estimation for Web Crawler System Design
Below is the capacity estimation of web crawler system design:
1. User Base
- Estimate target domains: 100 popular news, blog, and e-commerce websites.
- Average number of pages per website: 1000 pages.
- Frequency of updates: Daily.
- Total pages to crawl per day: 100 (websites) * 1000 (pages per website) = 100,000 pages/day.
2. Traffic Estimation
- Historical data shows peak usage of 10,000 requests per minute during special events.
- Predicted future traffic levels: 20% increase annually.
- Current peak traffic: 10,000 requests per minute.
- Estimated peak traffic next year: 10,000 * 1.2 = 12,000 requests per minute.
3. Handling Peak Loads
- Plan for auto-scaling to handle up to 5 times the normal load during special events.
- Normal load: 1000 requests per minute.
- Peak load handling capacity: 1000 * 5 = 5000 requests per minute.
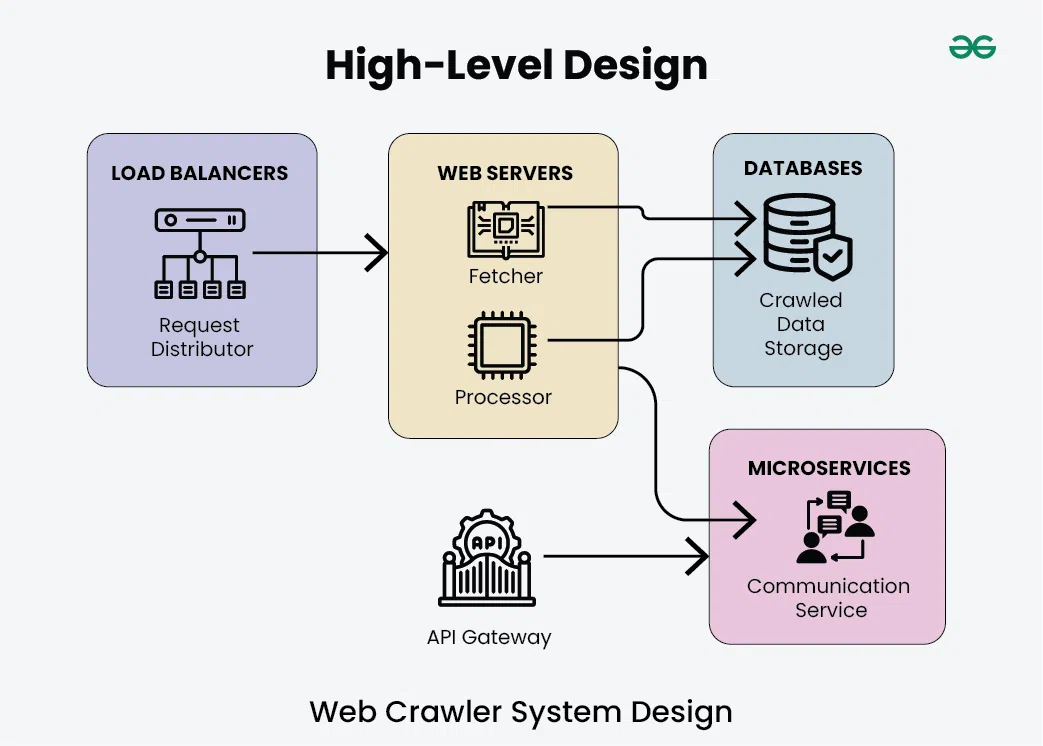
- The load balancer serves as the entry point for incoming requests to the web crawler system.
- The "Request Distributor" component within the load balancer distributes incoming requests among multiple web servers for load balancing and fault tolerance.
2. Web Servers
The web servers are responsible for fetching and processing web pages. Within the web servers section, there are two main components:
- Fetcher: This component fetches web pages from the internet based on the URLs provided.
- Processor: This component processes the fetched web pages, extracting relevant information and performing any required data processing or analysis.
3. Databases (Crawled Data Storage)
- The databases store the crawled data obtained from the processed web pages.
- This section represents the storage layer where crawled data is persisted for future retrieval and analysis.
4. Microservices (Communication Service)
- The microservices architecture includes a communication service responsible for facilitating communication between various components of the system.
- This section represents the interaction layer where microservices handle communication tasks such as message passing, event notification, and coordination between different parts of the system.
- The API gateway acts as the main entry point for external users to use the web crawler system. It combines all the different functions offered by the small software programs into a single, easy-to-use interface.
- This ensures that all requests are handled securely, that users are confirmed as who they say they are, and that the number of requests is controlled to prevent overloading.

The load balancer distributes incoming requests among multiple web servers to ensure load balancing and fault tolerance.
2. Web Servers
- There are three web server instances: Web Server 1, Web Server 2, and Web Server 3.
- These web servers handle incoming requests for fetching and processing web pages.
The Crawling Service is a microservice responsible for coordinating the crawling process. It consists of three components:
- Processing Service: This component processes the fetched web pages.
- Queue Service: This service manages the queue of URLs to be crawled.
- Cache Layer: This layer caches frequently accessed data to improve performance.
4. Databases
- The Databases section includes both NoSQL and relational databases for storing crawled data.
- These databases store the processed data obtained from the crawling process.
5. Additional Components
- Data Processing Pipeline: This component processes the crawled data before storing it in databases.
- Cache Layer: This layer caches data to improve system performance by reducing the load on databases.
- Monitoring Service: This service monitors the health and performance of web servers, microservices, and databases.
- API Gateway: The API Gateway serves as a central access point for external clients to interact with the microservices.
Database Design for Web Crawler System Design
.webp)
1. URLs Table
The URLs table stores information about the URLs encountered during crawling. It typically includes the following columns:
- URL: The URL of the web page.
- Status: The status of the URL (e.g., crawled, pending, error).
- Last Crawled: Timestamp indicating when the URL was last crawled.
- Depth: The depth of the URL in the crawl hierarchy (e.g., root, first-level link, second-level link)
2. Content Table
The content table stores the content extracted from crawled web pages. It may include columns such as:
- URL: The URL of the web page.
- Title: The title of the web page.
- Text Content: The main text content of the web page.
- Metadata: Any metadata associated with the web page (e.g., author, publish date).
- HTML Source: The raw HTML source code of the web page.
3. Links Table
The links table stores information about the links extracted from crawled web pages. It typically includes columns like:
- Source URL: The URL of the web page where the link was found.
- Target URL: The URL linked to from the source page.
- Anchor Text: The anchor text associated with the link.
- Link Type: The type of link (e.g., internal, external).
4. Index Table
The index table stores indexed information for efficient search and retrieval. It may include columns like:
- Keyword: The indexed keyword extracted from the content.
- URLs: The URLs associated with the indexed keyword.
- Frequency: The frequency of the keyword occurrence in the content.
5. Metadata Table
The metadata table stores additional metadata about crawled web pages. It can include columns like:
- URL: The URL of the web page.
- Content-Type: The MIME type of the web page (e.g., text/html, image/jpeg).
- Content-Length: The size of the web page content in bytes.
- HTTP Status Code: The HTTP status code returned when fetching the web page.
Microservices and API Used for Web Crawler System Design
1. Microservices used for Web Crawler System Design
- Crawler Service:
- Responsible for core crawling functionality.
- Exposes endpoints for managing crawling tasks.
- Database Service:
- Manages database operations.
- Provides endpoints for interacting with the database service.
- Queue Service:
- Manages the queue of URLs to be crawled.
- Offers endpoints for queue management.
- Analysis Service:
- Performs additional analysis on crawled data.
- Exposes endpoints for triggering analysis tasks.
- Notification Service:
- Sends notifications based on crawling events.
- Provides endpoints for notification management.
2. APIs Used for Web Crawler System Design
1. Crawler API:
Endpoints:
- /add-url
- /retrieve-data
- /start-crawl
Example Requests:
1. Adding URL to crawl:
{
"url": "https://example.com"
}
2. Retrieving crawled data:
{
"url": "https://example.com",
"data": "Crawled data content..."
}
3. Starting crawl:
{
"message": "Crawl started successfully"
}
2. Database API:
Endpoints:
Example Requests:
1. Storing crawled data:
{
"url": "https://example.com",
"data": "Crawled data content..."
}
2. Querying indexed information:
{
"query": "SELECT * FROM crawled_data WHERE keyword='example'"
}
3. Queue API:
Endpoints:
- /enqueue-url
- /dequeue-url
- /monitor-queue
Example Requests:
1. Enqueueing URL for crawling:
{
"url": "https://example.com"
}
2. Dequeueing URL from queue:
{
"url": "https://example.com"
}
3. Monitoring queue status:
{
"status": "Queue is running smoothly"
}
4. Analysis API:
Endpoints:
- /trigger-analysis
- /submit-data
- /retrieve-results
Example Requests:
1. Triggering analysis on crawled data:
{
"task": "Sentiment analysis",
"data": "Crawled data content..."
}
2. Submitting data for analysis:
{
"task": "Keyword extraction",
"data": "Crawled data content..."
}
3. Retrieving analysis results:
{
"task": "Sentiment analysis",
"result": "Positive"
}
5. Notification API:
Endpoints:
- /subscribe
- /configure-preferences
- /receive-updates
Example Requests:
1. Subscribing to notifications:
{
"email": "[email protected]"
}
2. Configuring notification preferences:
{
"preferences": {
"email": true,
"sms": false
}
}
3. Receiving real-time updates:
{
"event": "Crawl completed",
"message": "Crawl of https://example.com completed successfully"
}
Scalability for Web Crawler System Design
- Auto-scaling: Configure the system to automatically adjust server capacity based on workload demands, ensuring optimal performance during peak traffic periods and minimizing costs during low activity.
- Horizontal Scaling: Design the system to scale horizontally by adding more instances of components such as crawlers, queues, and databases, allowing it to handle increased traffic and processing requirements.
- Load Balancing: Implement load balancing techniques to evenly distribute incoming requests across multiple servers or instances, optimizing resource utilization and improving fault tolerance.
- Database Sharding: Distribute data across multiple database servers through sharding techniques, improving database performance, scalability, and fault tolerance by reducing data volume and query load on individual servers.
- Content Delivery Network (CDN): Utilize a CDN to cache and serve static assets from servers located closer to end-users, reducing latency, improving content delivery speed, and offloading traffic from origin servers.
Similar Reads
System Analysis | System Design In the areas of science, information technology, and knowledge, the difficulty of systems is of much importance. As systems became more complicated, the traditional method of problem-solving became inefficient. System analysis is to examine a business problem, identify its objectives and requirement
6 min read
Indexing in System Design System design is a complicated system that involves developing efficient and scalable solutions to satisfy the demands of modern applications. One crucial thing of system design is indexing, a way used to optimize information retrieval operations. In this article, we will delve into the idea of inde
12 min read
What are the components of System Design? The process of specifying a computer system's architecture, components, modules, interfaces, and data is known as system design. It involves looking at the system's requirements, determining its assumptions and limitations, and defining its high-level structure and components. The primary elements o
10 min read
Module Decomposition | System Design Module decomposition is a critical aspect of system design, enabling the breakdown of complex systems into smaller, more manageable modules or components. These modules encapsulate specific functionalities, making the system easier to understand, maintain, and scale. In this article, we will explore
9 min read
System Design - Live Course By GeeksforGeeks If you're preparing for a tech interview, especially for SDE 2 or SDE 3 job profiles - then you need to know you're required to have a sound knowledge of System Design concepts. Almost every IT giant whether it be Facebook, Amazon, Google, or any other asks various questions based on System Design c
5 min read
System Design Interview Questions and Answers [2025] In the hiring procedure, system design interviews play a significant role for many tech businesses, particularly those that develop large, reliable software systems. In order to satisfy requirements like scalability, reliability, performance, and maintainability, an extensive plan for the system's a
7 min read