How To Configure AWS Glue Data Integration?
Last Updated :
23 Sep, 2024
AWS Glue is a popular service designed to simplify data preparation from various sources, making it easier to ready data for analytics and machine learning tasks. By automating processes such as data loading and integration, it significantly reduces manual effort. As a serverless solution, AWS Glue focuses on seamless data integration and utilizes a centralized catalog to streamline data management and retrieval.
What Is AWS Glue?
AWS glue is a popular service which helps users to categorize the data and make sure it is clean and reliable as well. the architecture of AWS Glue has a primary metadata repository which is also known as the AWS Glue data catalog. it can easily handle the dependency as well as the monitoring of the jobs. the AWS glue service is completely serverless so there is no requirement for the setup of an infrastructure.
Now that we have some basic understanding of what AWS glue is and how it works, we can start understanding how to configure the data integration in glue step by step.
Following are the three different types of methods we can use for the configuration of AWS glue data integration:
We can use the projects menu offered by AWS glue and open the data which we want to make configurations and follow the below steps to configure the AWS data integration in glue, first, we will have to log in to the AWS account and then search for glue and on the left-hand side, select the PROJECTS option and then follow the steps.
Step 1: Select Data Column
- First we will have to select a particular data column in which we want to make the changes, we can perform almost any type of data change that we want here such as format, sort, split, duplicates and merge as well as functions and conditions on one or more columns.
 Select Data Column.
Select Data Column.Step 2: Select Required Change
- Next step is to select the required change tool that we want to use, there are various tools which are used in the AWS glue which can be used for configuration of the data integration such as sort, filter and functions etc. select the column you want to make changes in and then select the required tool from this menu.
 Select Required Change.
Select Required Change.Step 3: Apply The Changes
- As you can see in the image below, we have selected the merge columns option to make configuration in the data integration, for this we had to select one or more columns and then add the column name and click on the apply button to make the changes.
 Apply the Changes.
Apply the Changes.Step 4: Configuration Output
- As you can see in the image below, once we make the changes and click on the apply button the changes will be saved and reflected in the data of glue.
 Configuration Output.
Configuration Output.This is how we can make configurations in the AWS glue.
Method 2: Using Visual Mode In AWS Glue
Another method for making configuration changes in the AWS glue data integration is with the help of jobs which is a tool provided by AWS, for this simply follow the steps mentioned below.
Step 1: Open AWS Glue Jobs
- Go to AWS glue and go to data integration and ETL > Jobs and open it.
 Open AWS Glue Jobs.
Open AWS Glue Jobs.Step 2: Create Job For Glue
- Once you click on the jobs option, the jobs window will open and here we will have to select the option to create a visual with a source and target job which will allow us to define source and target for the data integration, so click on this and then click on the "create job" button.
 Create Job for Glue.
Create Job for Glue.Step 3: Make Changes Using Action
- Once the visual job options we can easily make changes using the action button, the action button is simply a option which helps us to choose from a set of options to make the required configurations to the data, we can choose actions such as aggregate, drop field, drop duplicates etc. just like we could in the method 1 as well.
 Make Changes using Action.
Make Changes using Action.This is a simpler step as compared to method 1 for those who are not used to data spreadsheets and want to make changes in the data more visually.
Method 3: Using Jupyter Notebook
Apart from the above steps we can also use the jupyter notebook to make changes one by one on the data using the jupyter notebook, this method is different from other methods as this method involves code to make configuration changes in the data.
These are some of the steps used for this method:
Step 1: Create Jupyter Notebook Job
- Just like we used the option of "visual with a source and target" option we will have to choose the jupyter notebook option to create a notebook job.
 Create Jupyter Notebook Job.
Create Jupyter Notebook Job.Step 2: Add The Execution Code
- Once the job is created, the jupyter notebook terminal will be opened in which we can execute the scripts and codes we want to make the changes we want to the data.
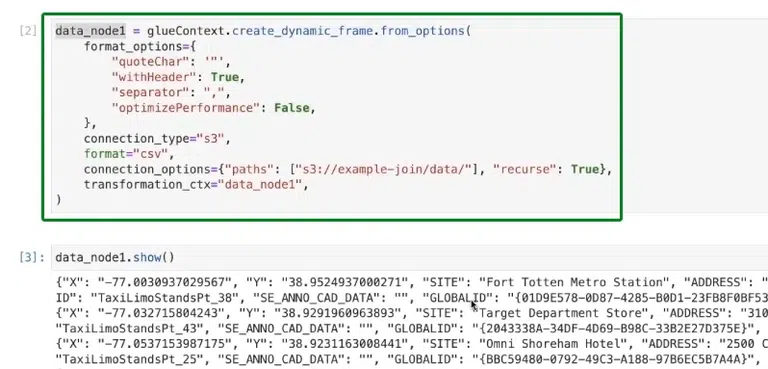
As you can see in the image below we are executing the following script in the jupyter notebook:
data_node1 = glueContext.create_dynamic_frame.from_options(
format_options={
"quoteChar": '',
"withHeader": True,
"separator": ",",
"optimizePerformance": False,
},
connection_type="s3",
format="csv",
connection_options={"paths": ["s3://example-join/data/"], "recurse": True},
transformation_ctx="data_node1",
)
Code Explanation
The glueContext.create_dynamic_frame.from_options method is called to read a CSV file from S3. The format_options parameter is used for specifying the characteristics of the CSV file, such as having headers, using a comma as a separator, and not using a quote character etc.
The connection_type is set to "s3", which means that the source of the data, and the format is set to "csv", specifying the type of the input data.
The connection_options parameter provides details on the S3 bucket and path to read the data from (s3://example-join/data/). The recurse option is set to True, meaning it will read all files in the specified directory and its subdirectories.
In the end, we have the transformation_ctx which is a string used to name the transformation, which can be helpful for tracking and debugging purposes. this code snippet sets up the necessary configurations for reading and processing CSV data from S3 using AWS Glue.
Output:
 Output.
Output.Best Practices To Setup AWS Glue Data Integration
Following are some of the best practices for the data integration using the AWS Glue:
- Use Partitioning And Compression: Partition data in Amazon S3 based on frequently queried columns to speed up ETL processing. use data compression formats like Parquet or ORC to reduce storage costs and improve job performance.
- Leverage Job Bookmarks: AWS Glue Job Bookmarks keep track of previously processed data to avoid duplicating work. Enable this feature to incrementally process new or modified data.
- Optimize Resource Allocation: Choose the appropriate worker type (Standard, G.1X, G.2X) based on your ETL workload requirements. Use AWS Glue Dynamic Frame filtering and partition pruning to minimize resource usage.
- Enable Glue Version Upgrades: Regularly update AWS Glue to the latest version to benefit from performance improvements and new features.
- Use AWS Glue Studio for Visual ETL Development: For users unfamiliar with coding, AWS Glue Studio provides a visual interface to create ETL workflows. This reduces the barrier to entry and simplifies complex ETL logic.
- Implement Data Quality Checks: Include data quality checks into your ETL jobs to validate the data against predefined rules. This helps maintain data integrity throughout the ETL process.
Troubleshooting Common Issues in AWS Glue Data Integration
There are not a lot of issues when we are working with AWS glue data integration, but following are a few common issues which can come in the AWS glue data integration so lets understand how we can overcome them with solution:
Job Failure Due To Resource Limits
- Issue: "ResourcesExceededException" error occurs when the job exceeds the allocated resources.
- Solution: Increase the number of DPU (Data Processing Unit) or select a more powerful worker type.
Crawler Fails to Recognize Schema
- Issue: The Glue Crawler does not detect the schema correctly or skips certain columns.
- Solution: Ensure the data is formatted correctly. If the data is inconsistent, consider using a custom classifier or manually define the schema in the Data Catalog.
Slow Job Execution
- Issue: Glue jobs are taking longer than expected to complete.
- Solution: Optimize job scripts, enable partition pruning, use smaller batch sizes, and select appropriate worker types.
Error: "Permission Denied"
- Issue: Insufficient IAM permissions for AWS Glue to access resources.
- Solution: Review the IAM policies attached to the Glue service role and ensure they have the required permissions.
Data Integrity Issues
- Issue: Data discrepancies between source and target.
- Solution: Perform data validation checks and reconciliation between source and target systems after job execution.
Conclusion
By using the AWS glue we can easily configure the data integration with more accuracy and use it in analytics as well as other applications such as machine learning. it is important to include AWS glue in the projects if possible because it can reduce the amount of manual work required for jobs with the help of automation which will lead to more efficiency.
Similar Reads
How To Configure SAML In AWS For enterprises configuring the SAML(Security Assertion Markup Language) is essential for providing an optimized and secured approach to user authentication and authorization. This article guides you in implementing the essential steps within the AWS ecosystem from making an understanding of SAML fu
9 min read
How to Configure AWS Direct Connect Setup? The setup for AWS Direct Connect involves creating a connection, configuring your on-premises routers, setting up virtual interfaces, establishing BGP peering, and thoroughly testing the connection. Once deployed, Direct Connect offers enhanced security, speed, and reliability for cloud access, outp
9 min read
AWS CLI for Continuous Integration Quick and efficient delivery of quality code is at the core of software development in the fast-paced arena. Practically, Continuous Integration (CI) has emerged as a lynchpin practice to this aim, where developers regularly integrate changes in the code into the shared repository. These integration
6 min read
How to Configure AWS Elasticsearch For Full-Text Search? The Elasticsearch built on Apache Lucene is a search and analytics engine . Since from its release in (2010), Elasticsearch has become one of the most popular search engine and a compulsion used for log analytics, full-text search, security intelligence and operational intelligence cases. To ensure
5 min read
How to Create AWS Data Lake In the data-driven world, organizations are flooded with large amounts of data that originate from various sources, ranging from structured databases to unstructured files and logs. In order to effectively make use of this data for insights and decisions, organisations need to have a storage system
15 min read