
随着 AI 工作负载的扩展,快速可靠的 GPU 通信变得至关重要,这不仅适用于训练,而且越来越适用于大规模推理。NVIDIA 集合通信库 (NCCL) 可提供高性能、拓扑感知型集合运算:AllReduce、Broadcast、Reduce、AllGather 和 ReduceScatter,这些运算已针对 NVIDIA GPU 以及 PCIe、NVLink、以太网 (RoCE) 和 InfiniBand (IB) 等各种互连产品进行优化。
凭借其通信和计算的单核实现,NCCL 可确保低延迟同步,成为分布式训练和实时推理场景的理想选择。得益于 NCCL 动态拓扑检测和简化的基于 C 的 API,开发者无需调整特定硬件配置即可跨节点进行扩展。
本文将介绍最新的 NCCL 2.27 版本,展示可增强推理延迟、训练弹性和开发者可观察性的功能。如需了解详情并开始使用,请查看 NVIDIA/nccl GitHub 存储库。
解锁新的性能水平
NCCL 2.27 提供关键更新,可增强跨 GPU 的聚合通信,解决延迟、带宽效率和扩展挑战。这些改进支持训练和推理,符合现代 AI 基础设施不断变化的需求,其中超低延迟对于实时推理流程至关重要,并且需要强大的容错能力来保持大规模部署的可靠运行。
主要版本亮点包括具有对称内存的低延迟内核、直接 NIC 支持以及 NVLink 和 InfiniBand SHARP 支持。
具有对称内存的低延迟内核
此版本引入了对称内存支持,允许跨 GPU 具有相同虚拟地址的缓冲区从优化的集合运算中受益。这些内核可显著降低各种消息大小的延迟,使小消息大小的延迟最多可降低 7.6 倍,如图 1 所示。

AllReduce 延迟使用 FP32 累加器 (或 FP16 用于 NVLink Switch (NVLS) 系统上的 FP8) 计算缩减,从而提高 AllReduce、tg_ 11 和 tg_ 12 等运算中的准确性和确定性。
单个 NVLink 域内的 NVLink 通信支持对称内存 – NVIDIA GB200 和 GB300 系统中支持 NVL72 ( 72 个 GPU) ,NVIDIA DGX 和 HGX 系统中支持 NVL8 ( 8 个 GPU) 。即使在 NVL8 域中,开发者也能看到中小型消息大小的性能提升高达 2.5 倍。有关测试指导,请查看 NCCL-Test 存储库。
直接网卡支持
NCCL 2.27 引入了对 Direct NIC 配置的支持,可为 GPU 横向扩展通信解锁完整的网络带宽。在选定的 NVIDIA Grace Blackwell 平台上,CX8 网卡和 NVIDIA Blackwell GPU 等组件支持 PCIe Gen6 x16,可提供高达 800 Gb/s 的网络带宽。但是,Grace CPU 目前仅支持 PCIe 5.0,将吞吐量限制在 400 Gb/s。
为了解决这个问题,CX8 网卡暴露了两个虚拟 PCIe 树:在一个树上,如图 2 所示,NVIDIA CX8 网卡数据直接功能 ( PF) 通过 PCIe Gen6 x16 链路直接连接到 GPU PF,绕过 CPU,避免了带宽瓶颈。在另一个树中,常规 NIC PF 连接到 CPU 根端口。
此配置可确保 GPUDirect RDMA 和相关技术能够实现完整的 800 Gb/s 带宽,而不会使 CPU 到 GPU 的带宽饱和,这在多个 GPU 共享单个 CPU 时尤为重要。Direct NIC 是为高吞吐量推理和训练工作负载实现全速网络的关键。

支持 NVLink 和 InfiniBand SHARP
NCCL 2.27 为 NVLink 和 IB 结构增加了对 SHARP (可扩展分层聚合和归约协议) 的支持。SHARP 支持网络内归约操作,可卸载计算密集型任务。在使用 NVLink Sharp 和 IB Sharp 时,此新版本为从 GPU 到网络的 AllGather (AG) 和 tg_ 15 (RS) 群集提供 SHARP 支持。
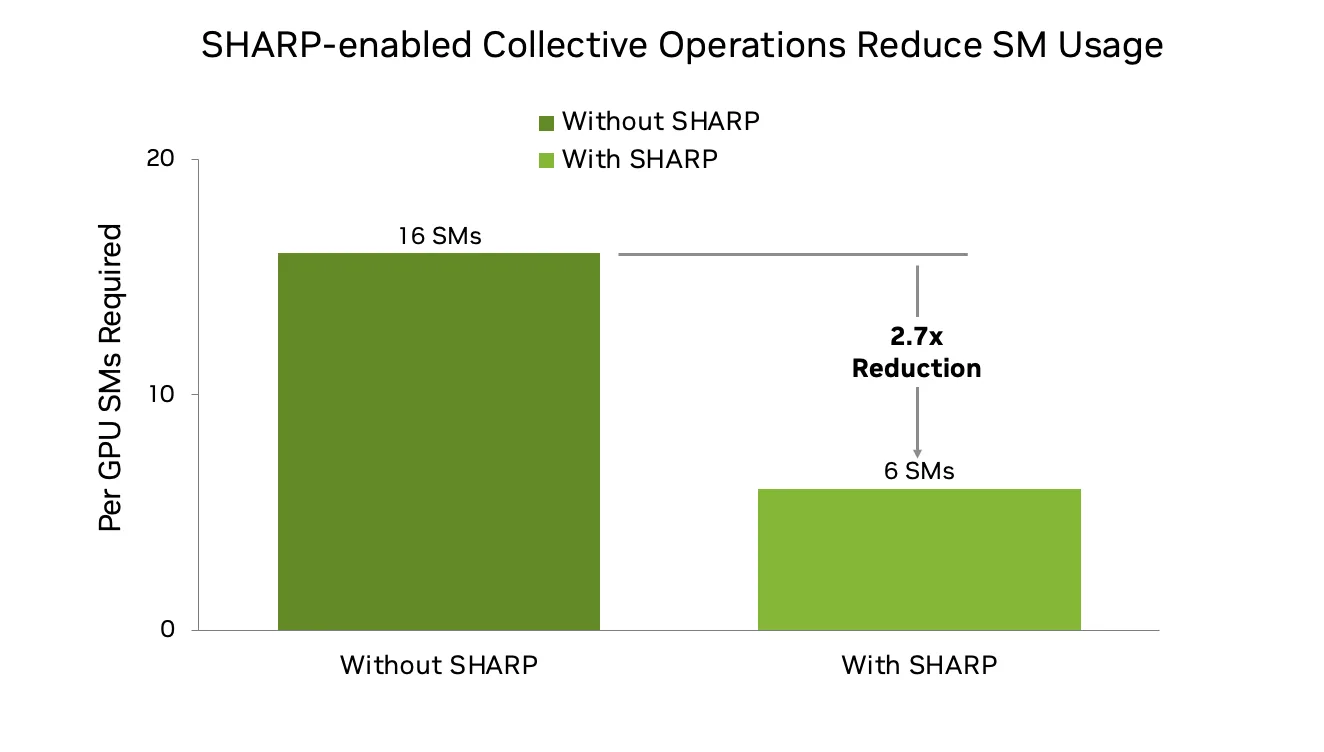
这对于大规模 LLM 训练尤其有益,因为在大规模 LLM 训练中,为了更好地重叠计算和通信,AG 和 RS 现在比 AllReduce 更受欢迎。传统的基于环的实现可能会消耗 16 个或更多的 SM,但借助 NVLink 和 IB SHARP,这种需求减少到 6 个或更少,从而腾出资源用于模型计算,并提高整体训练效率。因此,在 1000 GPU 级别及以上的情况下,可扩展性和性能得到了提升。
使用 NCCL Shrink 增强大规模训练的弹性
NCCL 2.27 引入了 Communicator Shrink,该功能旨在使分布式训练更加稳健、灵活和高效。在数百或数千个 GPU 上运行的训练作业容易受到设备故障的影响。Communicator Shrink 支持在训练期间动态排除出现故障或不必要的 GPU。此功能支持两种操作模式:
- 默认模式:用于有计划的重新配置,允许修改设备拓扑,同时确保完成所有操作。
- 错误模式:自动中止正在进行的操作,以从意外的设备故障中恢复。
NCCL Shrink 使开发者能够:
- 通过动态重建通信器保持不间断训练。
- 通过可配置的资源共享尽可能重复使用资源。
- 以最少的中断妥善处理设备故障。
NCCL Shrink 在计划的重新配置和错误恢复场景中的使用示例:
// Planned reconfiguration: exclude a rank during normal operation
NCCLCHECK(ncclGroupStart());
for (int i = 0; i < nGpus; i++) {
if (i != excludedRank) {
NCCLCHECK(ncclCommShrink(
comm[i], &excludeRank, 1,
&newcomm[i], NULL, NCCL_SHRINK_DEFAULT));
}
}
NCCLCHECK(ncclGroupEnd());
// Error recovery: exclude a rank after a device failure
NCCLCHECK(ncclGroupStart());
for (int i = 0; i < nGpus; i++) {
if (i != excludedRank) {
NCCLCHECK(ncclCommShrink(
comm[i], &excludeRank, 1,
&newcomm[i], NULL, NCCL_SHRINK_ABORT));
}
}
NCCLCHECK(ncclGroupEnd());
面向开发者的更多功能
此版本中面向开发者的其他功能包括对称内存 API 和增强型分析。
对称内存 API
对称内存是 NCCL 2.27 中的一项基础功能,可实现高性能、低延迟的集合运算。当内存缓冲区在所有 rank 上以相同的虚拟地址分配时,NCCL 可以执行经过优化的内核,从而减少同步开销并提高带宽效率。
为此,NCCL 引入了用于对称内存集合注册的窗口 API:
ncclCommWindowRegister(ncclComm_t comm, void* buff, size_t size,
ncclWindow_t* win, int winFlags);
ncclCommWindowDeregister(ncclComm_t comm, ncclWindow_t win);
ncclCommWindowRegister使用 NCCL 通信器注册用户分配的内存。必须使用 CUDA 虚拟内存管理 (VMM) API 分配内存。winFlags必须包含 tg_ 22 才能启用对称内核优化。- 所有 rank 必须为缓冲区提供匹配偏移量,以确保对称寻址。
- 取消注册 (
ncclCommWindowDeregister) 是一项本地操作,只能在所有相关集合完成后进行。
ncclCommWindowRegister 是集合和阻塞,这意味着当多个 GPU 由单个线程管理时,它们必须封闭在 tg_ 25 和 tg_ 26 中。
如果不需要对称内存,用户可以通过设置 NCCL_WIN_ENABLE=0 来完全禁用该功能。
图 4 显示了如何使用 NCCL 窗口 API 在多个 GPU 上注册对称内存。通过对齐虚拟地址,NCCL 可实现经过优化的低延迟内核,从而提高集合运算的性能。

增强型分析
NCCL 2.27 为其分析基础设施引入了一系列增强功能,为开发者和工具提供更准确、更高效的仪器来诊断通信性能。
协调代理事件
之前,NCCL 公开了 ncclProfileProxyOp 和 ncclProfileProxyStep 事件,以跟踪网络代理线程的进度。虽然这些事件提供了不同级别的粒度,但它们也复制了许多仪器点。在版本 2.27 中,NCCL 通过删除冗余的 ProxyOp 状态并引入统一的 tg_ 32 状态来简化此模型。这可在不牺牲细节的情况下减少分析器开销,并在跟踪通信进度时提高清晰度。
此外,我们还引入了新的 ProxyStep 事件状态:tg_ 34,以反映发送者秩等待接收者发布清晰发送信号的时间,在集成之前的功能的同时最大限度地减少重复。
GPU 内核事件准确性
为提高计时准确性,NCCL 现在支持原生 GPU 时间传播。GPU 工作计数器是一种容易受到延迟伪影 (例如延迟或折叠的核函数) 影响的方法,不再依赖于主机侧事件计时,现在 GPU 使用其内部全局计时器记录和导出开始和停止时间。这使分析器工具能够直接从 GPU 获取精确的内核运行时持续时间,但将时间转换为 CPU 时间的开发者需要应用校准或插值。
网络插件事件更新
NCCL 分析器接口现在支持用于网络定义事件的 recordEventState。这种新机制使分析器能够更新正在进行的操作的状态,这对于将实时网络反馈注入到性能时间线 (例如转发信号或拥塞提示) 非常有用。
其他增强功能
- 分析器初始化:在分析器初始化期间,NCCL 现在报告通信器元数据,包括名称、ID、节点数量、等级数量和调试级别。
- 通道报告:报告的通道数量反映的是实际使用情况,而非理论限制。其中包括点对点 (P2P) 操作。
- Communicator 标记:
ncclConfig_t已扩展为包含 Communicator 名称,从而提高分析操作与特定 Communicator 之间的相关性。
这些更新共同提高了 NCCL 分析器插件接口的保真度,使开发者能够更深入地了解网络动态、GPU 计时和操作结构,这些对于诊断和调整大规模 AI 工作负载至关重要。
有关 NCCL Profiler 插件的更多信息,请参阅 NVIDIA/nccl GitHub 资源库。
前瞻性支持
前瞻性支持包括:
- 跨数据中心通信:早期支持允许跨分布在各地的数据中心进行集合操作。
- 多网卡插件可见性:支持同时利用多种网络配置。
开始使用 NCCL 2.27
探索 NCCL 2.27 中的新功能,并通过更低的延迟、更高的容错性和更深入的可观测性提升分布式推理和训练工作流。
如需获取详细文档和源代码,以及获取所需的支持,请访问 NVIDIA/nccl GitHub 资源库。如需详细了解为您的架构配置 NCCL,请参阅 NCCL 文档。




