NVIDIA NeMo Retriever
NVIDIA NeMo™ Retriever is a collection of microservices that provide world-class information retrieval with high accuracy and maximum data privacy. Use NeMo Retriever to generate quick, context-aware responses from large collections of data. Built with NVIDIA NIM™, NeMo Retriever lets you flexibly leverage fine-tuned microservices to build AI query engines with scalable document ingestion and advanced retrieval-augmented generation (RAG), connecting AI applications to varied data types, wherever they reside.
Documentation
Build information-retrieval pipelines and next-gen AI applications for multimodal data ingestion, embedding, reranking, RAG, and agentic AI workflows.
Ingestion
Rapidly ingest massive volumes of data and extract text, graphs, charts, and tables at the same time for highly accurate retrieval.
Embedding
Boost text question-and-answer retrieval performance, providing high-quality embeddings for many downstream natural language processing (NLP) tasks.
Reranking
Enhance retrieval performance further with a fine-tuned reranking model, finding the most relevant passages to provide as context when querying a large language model (LLM).
How NVIDIA NeMo Retriever Works
NeMo Retriever provides the components needed to build data ingestion and information retrieval pipelines. The ingestion pipeline extracts structured and unstructured data, including text, charts, documents, and tables, converting it to text and filtering it to avoid duplicate chunks.
The extracted data is fed into a retrieval pipeline. A NeMo Retriever converts the chunks into embeddings and stores them in a vector database, accelerated by NVIDIA cuVS, for enhanced performance and speed of indexing and search.
When you submit a query, the relevant information is retrieved from the vast repository of ingested knowledge. The embedding NIM embeds the user query and retrieves the most relevant chunks using vector similarity search from the vector database.
A NeMo Retriever reranking NIM evaluates and reranks the results to ensure the most accurate and useful chunks are used to augment the prompt. With the most pertinent information at hand, the LLM NIM generates a response that’s informed, accurate, and contextually relevant. You can use various LLM NIM microservices from the NVIDIA API catalog to enable additional capabilities such as synthetic data generation. And with NVIDIA NeMo, you can fine-tune the LLM NIM microservices to better align with specific use case needs.
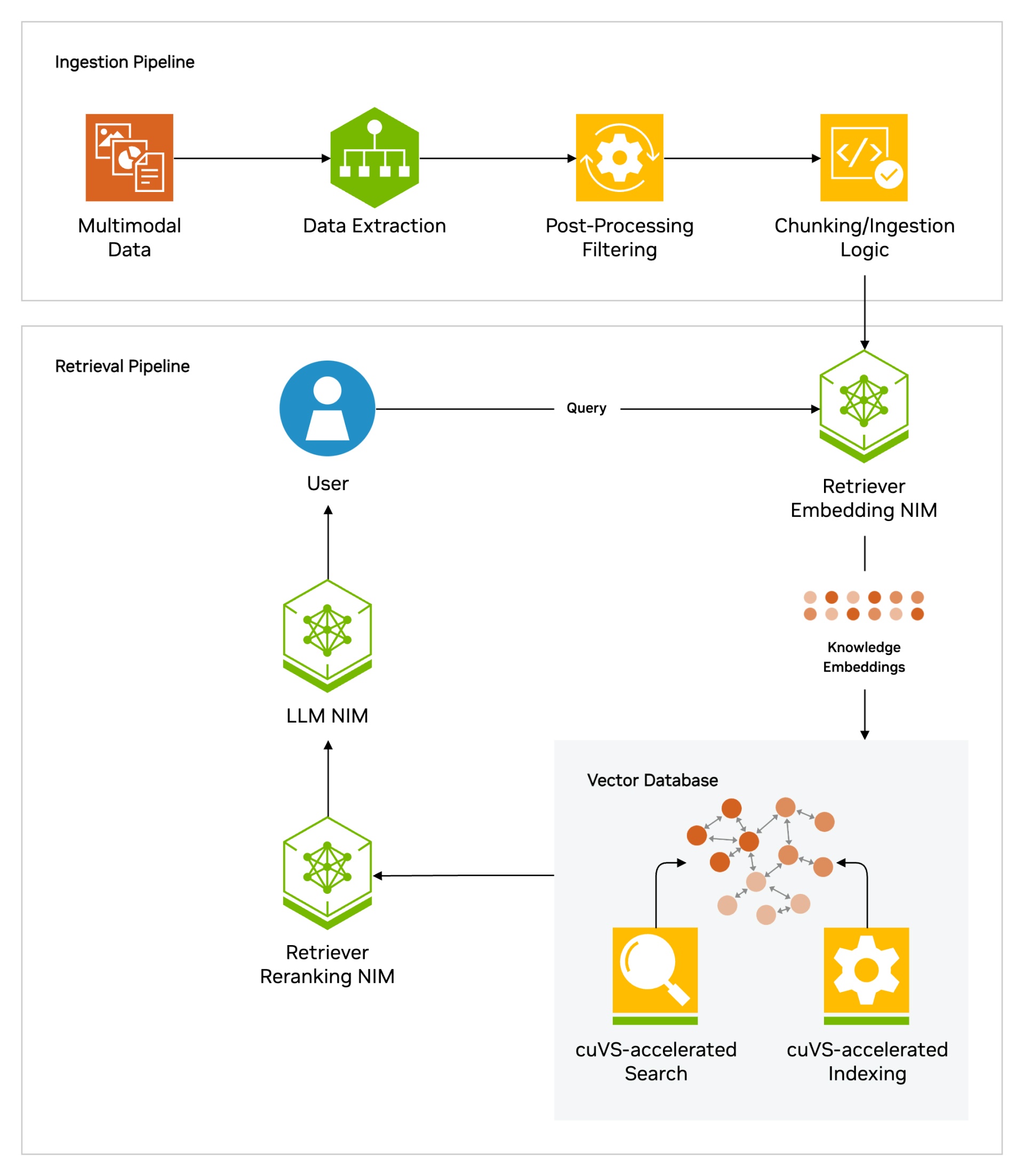
NVIDIA NeMo Retriever collection of NIM microservices are used to build optimized ingestion and retrieval pipelines for highly accurate information retrieval at scale.
Introductory Resources
Learn more about building efficient information-retrieval pipelines with NeMo Retriever.
Introductory Blog
Understand the function of embedding and reranking models in information-retrieval pipelines, top considerations, and more.
Read BlogIntroductory Webinar
Improve the accuracy and scalability of text retrieval for production-ready generative AI pipelines and deploy at scale.
Watch NowAI Blueprint for RAG
Learn best practices for connecting AI apps to enterprise data using industry-leading embedding and reranking models.
World-Class Information-Retrieval Performance
NeMo Retriever provides leading retrieval embedding accuracy and enables enterprise-scale document ingestion, fast retrieval with higher throughput, and better accuracy with fewer incorrect answers. It also improved vector storage volume with long-context support, dynamic embeddings, and efficient storage for high-performance, scalable data processing.
2X Throughput for Fast Retrieval
Multilingual Text Embedding Model

NIM Off: FP16, P90 latency: ~3.8s
NIM On: FP8, P90 latency: ~1.8s
30% Fewer Incorrect Answers
Text Embedding and Reranking

NVIDIA Wins: MTEB Leaderboard
NeMo Retriever Models
.svg)
35x Improved Data Storage Efficiency
Multilingual, Long-Context, Text Embedding Model
.svg)
Ways to Get Started With NVIDIA NeMo Retriever
Use the right tools and technologies to build and deploy generative AI applications that require secure and accurate information retrieval to generate real-time business insights for organizations across every industry.

Try
Experience NeMo Retriever NIM microservices through a UI-based portal for exploring and prototyping with NVIDIA-managed endpoints, available for free through NVIDIA’s API catalog and deployed anywhere.
Microservices

Experience
Access NVIDIA-hosted infrastructure and guided hands-on labs that include step-by-step instructions and examples, available for free on NVIDIA Launchpad.
Labs
Build
Jump-start building your AI solutions with NVIDIA Blueprints, customizable reference applications, available on the NVIDIA API catalog.

Deploy
Get a free license to try
NVIDIA AI Enterprise in production for 90 days using your existing infrastructure.
License
Starter Kits
Start building information retrieval pipelines and generative AI applications for multimodal data ingestion, embedding, reranking, retrieval-augmented generation, and agentic workflows by accessing NVIDIA Blueprints, tutorials, notebooks, blogs, forums, reference code, comprehensive documentation, and more.
AI Assistant for Customer Service
Build enhanced AI assistants that are more personalized and secure by leveraging RAG, NeMo Retriever, NIM, and the latest AI agent-building methodologies.
Retail Shopping Assistant
Develop a multimodal RAG application powered by LLMs that enables more personalized shopping experiences.
AI Chatbot Using RAG
Build an AI chatbot using RAG that can accurately generate responses based on your enterprise data.
Multimodal PDF Data Extraction for Enterprise RAG
Build an enterprise-scale pipeline that can ingest and extract highly accurate insights contained in text, graphs, charts, and tables within massive volumes of PDF documents.
Digital Human for Customer Service
Bring applications to life with an AI-powered digital avatar that can transform customer service experiences.
Visual Agent for Video Search and Summarization
Ingest massive volumes of live or archived videos and extract insights for summarization and interactive Q&A.
NVIDIA NeMo Retriever Learning Library
More Resources


Ethical AI
NVIDIA’s platforms and application frameworks enable developers to build a wide array of AI applications. Consider potential algorithmic bias when choosing or creating the models being deployed. Work with the model’s developer to ensure that it meets the requirements for the relevant industry and use case; that the necessary instruction and documentation are provided to understand error rates, confidence intervals, and results; and that the model is being used under the conditions and in the manner intended.
Stay up to date on the latest generative AI news from NVIDIA.