
A major challenge in robotics is training robots to perform new tasks without the massive effort of collecting and labeling datasets for every new task and environment. Recent research efforts from NVIDIA aim to solve this challenge through the use of generative AI, world foundation models (WFMs) like NVIDIA Cosmos, and data generation blueprints such as NVIDIA Isaac GR00T-Mimic and GR00T-Dreams.
This edition of NVIDIA Robotics Research and Development Digest (R2D2) covers how research is enabling scalable synthetic data generation and robot model training workflows using world foundation models, such as:
- DreamGen: The research foundation of the NVIDIA Isaac GR00T-Dreams blueprint.
- GR00T N1: An open foundation model that enables robots to learn generalist skills across diverse tasks and embodiments from real, human, and synthetic data.
- Latent Action Pretraining from Videos: An unsupervised method that learns robot-relevant actions from large-scale videos without requiring manual action labels.
- Sim-and-Real Co-Training: A training approach that combines simulated and real-world robot data to build more robust and adaptable robot policies.
World foundation models for robotics
Cosmos world foundation models (WFMs) are trained on millions of hours of real-world data to predict future world states and generate video sequences from a single input image, enabling robots and autonomous vehicles to anticipate upcoming events. This predictive capability is crucial for synthetic data generation pipelines, facilitating the rapid creation of diverse, high-fidelity training data. This approach significantly accelerates robot learning, enhances model robustness, and reduces development time from months of manual effort to just hours.
DreamGen
DreamGen is a synthetic data generation pipeline that addresses the high cost and labor of collecting large-scale human teleoperation data for robot learning. It is the basis for NVIDIA Isaac GR00T-Dreams, a blueprint for generating vast synthetic robot trajectory data using world foundation models.
Traditional robot foundation models require extensive manual demonstrations for every new task and environment, which isn’t scalable. Simulation-based alternatives often suffer from the sim-to-real gap and require heavy manual engineering.
DreamGen overcomes these challenges by using world foundation models to create realistic, diverse training data with minimal human input. This approach enables scalable robot learning and strong generalization across behaviors, environments, and robot embodiments.

The DreamGen pipeline consists of four key steps:
- Post-train world foundation model:
Adapt a world foundation model like Cosmos-Predict2 to the target robot using a small set of real demonstrations. Cosmos-Predict2 generates high-quality images from text (text-to-image) and visual simulations from images or videos (video-to-world). - Generate synthetic videos:
Use the post-trained model to create diverse, photorealistic robot videos for new tasks and environments from image and language prompts. - Extract pseudo-actions:
Apply a latent action model or inverse dynamics model (IDM) to turn these videos into labeled action sequences (neural trajectories). - Train robot policies:
Use the resulting synthetic trajectories to train visuomotor policies, enabling robots to perform new behaviors and generalize to unseen scenarios.

DreamGen Bench
DreamGen Bench is a specialized benchmark designed to evaluate how effectively video generative models adapt to specific robot embodiments while internalizing rigid-body physics and generalizing to new objects, behaviors, and environments. It tests four leading world foundation models—NVIDIA Cosmos, WAN 2.1, Hunyuan, and CogVideoX—measuring two critical metrics:
- Instruction following: Assesses whether generated videos accurately reflect task instructions (e.g., “pick up the onion”), evaluated using VLMs like Qwen-VL-2.5 and human annotators.
- Physics following: Quantifies physical realism using tools like VideoCon-Physics and Qwen-VL-2.5 to ensure videos obey real-world physics.
As seen in Figure 3, we observe that models scoring higher on DreamGen Bench—meaning they generate more realistic and instruction-following synthetic data—consistently lead to better performance when robots are trained and tested on real manipulation tasks. This positive relationship shows that investing in stronger world foundation models not only improves the quality of synthetic training data but also translates directly into more capable and adaptable robots in practice.

NVIDIA Isaac GR00T-Dreams
Isaac GR00T-Dreams, based on DreamGen research, is a workflow for generating large datasets of synthetic trajectory data for robot actions. These datasets are used to train physical robots while saving significant time and manual effort compared to collecting real-world action data.
GR00T-Dreams uses the Cosmos Predict2 WFM and Cosmos Reason to generate data for different tasks and environments. Cosmos Reason models include a multimodal LLM (large language model) that generates physically grounded responses to user prompts.
Models and workflows for training generalist robots
Vision language action (VLA) models can be post-trained using data generated from WFMs to enable novel behaviors and operations in unseen environments.
NVIDIA Research used the GR00T-Dreams blueprint to generate synthetic training data to develop GR00T N1.5, an update of GR00T N1 in just 36 hours. This process would have taken nearly three months using manual human data collection.
GR00T N1, the world’s first open foundation model for generalist humanoid robots, marks a major breakthrough in the world of robotics and AI. Built on a dual-system architecture inspired by human cognition, GR00T N1 unifies vision, language, and action, enabling robots to understand instructions, perceive their environment, and execute complex, multi-step tasks.
GR00T N1 builds on techniques like LAPA to learn from unlabeled human videos and approaches like sim-and-real co-training, which blends synthetic and real-world data for stronger generalization. We’ll learn about LAPA and sim-and-real co-training later in this blog. By combining these innovations, GR00T N1 doesn’t just follow instructions and execute tasks—it sets a new benchmark for what generalist humanoid robots can achieve in complex, ever-changing environments.
GR00T N1.5 is an upgraded open foundation model for generalist humanoid robots, building on the original GR00T N1, which features a refined vision-language model trained on a diverse mix of real, simulated, and DreamGen-generated synthetic data.
With improvements in architecture and data quality, GR00T N1.5 delivers higher success rates, better language understanding, and stronger generalization to new objects and tasks, making it a more robust and adaptable solution for advanced robotic manipulation.
Latent Action Pretraining from Videos
Latent Action Pretraining for general Action models (LAPA) is an unsupervised method for pre-training Vision-Language-Action (VLA) models that removes the need for expensive, manually labeled robot action data. Rather than relying on large, annotated datasets—which are both costly and time-consuming to gather—LAPA uses over 181,000 unlabeled Internet videos to learn effective representations.
This method delivers a 6.22% performance boost over advanced models on real-world tasks and achieves more than 30x greater pretraining efficiency, making scalable and robust robot learning far more accessible and efficient.
The LAPA pipeline operates through a three-stage process:
- Latent action quantization: A Vector Quantized Variational AutoEncoder (VQ-VAE) model learns discrete “latent actions” by analyzing transitions between video frames, creating a vocabulary of atomic behaviors (e.g., grasping, pouring). Latent actions are low-dimensional, learned representations that summarize complex robot behaviors or motions, making it easier to control or imitate high-dimensional actions.
- Latent pretraining: A VLM is pre-trained using behavior cloning to predict these latent actions from the first stage based on video observations and language instructions. Behavior cloning is a method where a model learns to copy or imitate actions by mapping observations to actions, using examples from demonstration data.
- Robot post-training: The pretrained model is then post-trained to adapt to real robots using a small labeled dataset, mapping latent actions to physical commands.

Sim-and-Real Co-Training workflow
Robotic policy training faces two critical challenges: the high cost of collecting real-world data and the “reality gap,” where policies trained only in simulation often fail to perform well in real physical environments.
The Sim-and-Real Co-Training workflow addresses these issues by combining a small set of real-world robot demonstrations with large amounts of simulation data. This approach enables the training of robust policies while effectively reducing costs and bridging the reality gap.
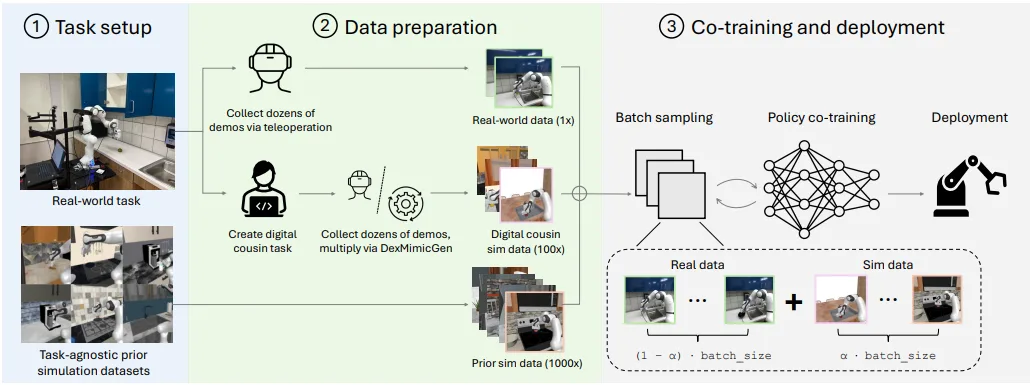
The key steps in the workflow are:
- Task and scene setup: Setup of a real-world task and the selection of task-agnostic prior simulation datasets.
- Data preparation: In this data preparation stage, real-world demonstrations are collected from physical robots, while additional simulated demonstrations are generated, both as task-aware “digital cousins,” which closely match the real tasks, and as diverse, task-agnostic prior simulations.
- Co-training parameter tuning: These different data sources are then blended at an optimized co-training ratio, with an emphasis on aligning camera viewpoints and maximizing simulation diversity rather than photorealism. The final stage involves batch sampling and policy co-training using both real and simulated data, resulting in a robust policy that is deployed on the robot.

As shown in Figure 7, increasing the number of real-world demonstrations improves the success rate for both real-only and co-trained policies. Even with 400 real demonstrations, the co-trained policy consistently outperforms the real-only policy by an average of 38%, demonstrating that sim-and-real co-training remains beneficial even in data-rich settings.

Ecosystem adoption
Leading organizations are adopting these workflows from NVIDIA research to accelerate development. Early adopters of GR00T N models include:
- AeiRobot: Using the models to enable its industrial robots to understand natural language for complex pick-and-place tasks.
- Foxlink: Leveraging the models to improve the flexibility and efficiency of its industrial robot arms.
- Lightwheel: Validating synthetic data for the faster deployment of humanoid robots in factories using the models.
- NEURA Robotics: Evaluating the models to accelerate the development of its household automation systems.
Getting started
Explore these resources to dive in:
- DREAMGEN: Project Website, Paper, GitHub
- NVIDIA Isaac GR00T-Dreams: GitHub
- NVIDIA Isaac GR00T N1.5: Project Website, Paper, Model, GitHub
- Latent Action Pretraining from Videos: Project Website, Paper, Model, GitHub
- Sim-and-Real Co-Training: Project Website, Paper
- NVIDIA Cosmos: Cosmos Predict2, Cosmos Reason, Cosmos Transfer, Cosmos benchmark
This post is part of our NVIDIA Robotics Research and Development Digest (R2D2) to give developers a deeper insight into the latest breakthroughs from NVIDIA Research across physical AI and robotics applications.
Learn more about NVIDIA Research and stay up to date by subscribing to the newsletter and following NVIDIA Robotics on YouTube, Discord, and developer forums. To start your robotics journey, enroll in our free NVIDIA Robotics Fundamentals courses today.
Acknowledgments
For their contributions to the research mentioned in this post, thanks to Johan Bjorck, Lawrence Yunliang Chen, Nikita Chernyadev, Yu-Wei Chao, Bill Yuchen Lin, Lin Yen-Chen, Linxi ‘Jim ’Fan, Dieter Fox, Yu Fang, Jianfeng Gao, Ken Goldberg, Fengyuan Hu, Wenqi Huang, Spencer Huang, Zhenyu Jiang, Byeongguk Jeon, Sejune Joo, Jan Kautz, Joel Jang, Kaushil Kundalia, Kimin Lee, Lars Liden, Zongyu Lin, Ming-Yu Liu, Loic Magne, Abhiram Maddukuri, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Baolin Peng, Scott Reed, Reuben Tan, You Liang Tan, Jing Wang, Qi Wang, Guanzhi Wang, Zu Wang, Jianwei Yang, Seonghyeon Ye, Yuke Zhu, Yuqi Xie, Jiannan Xiang, Zhenjia Xu, Yinzhen Xu, Xiaohui Zeng, Kaiyuan Zheng, Ruijie Zheng, Luke Zettlemoyer









