本頁面說明如何使用 Cloud SQL 系統洞察資訊儀表板。「系統深入分析」資訊主頁會顯示執行個體使用的資源指標,並協助您偵測及分析系統效能問題。
您可以使用資料庫輔助功能中的 Gemini,協助觀察及排解 PostgreSQL 適用的 Cloud SQL 資源的問題。詳情請參閱「使用 Gemini 協助功能觀察及排解問題」。查看「系統深入分析」資訊主頁
如要查看「系統洞察」資訊主頁,請按照下列步驟操作:
-
前往 Google Cloud 控制台的「Cloud SQL 執行個體」頁面。
- 按一下執行個體的名稱。
在左側的 SQL 導覽面板中,選取「系統深入分析」分頁標籤。
系統洞察資訊主頁會隨即開啟。

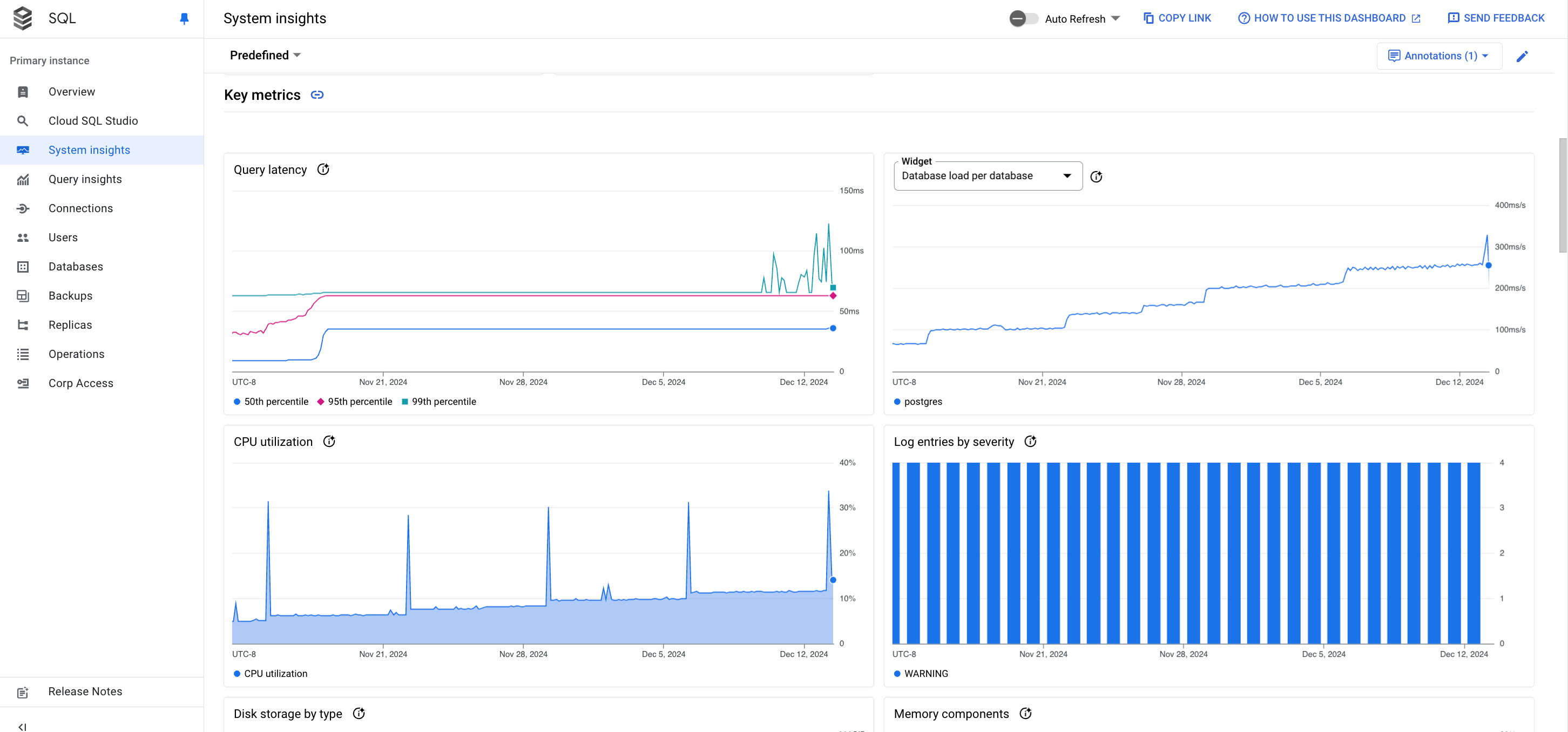
「系統洞察」資訊主頁會顯示下列資訊:
執行個體詳細資料
事件時間軸:依時間順序顯示系統事件。這項資訊有助您評估系統事件對執行個體健康和效能造成的影響。
摘要資訊卡:顯示 CPU 使用率、磁碟使用率和記錄錯誤指標的最新值和匯總值,概略說明執行個體的健康狀態和效能。
指標圖表:顯示作業系統和資料庫指標的相關資訊,協助您深入瞭解多項問題,例如吞吐量、延遲時間和成本。
資訊主頁提供下列高階選項:
- 每列顯示一或兩個圖表。點選「自訂檢視畫面」,選擇這些圖表的顯示方式。您也可以使用這個選項,選擇要顯示在資訊主頁的指標。
如要讓資訊主頁保持最新狀態,請啟用
 「自動重新整理」選項。啟用「自動重新整理」後,資訊主頁資料會每分鐘更新一次。這項功能與自訂時間範圍不相容。
「自動重新整理」選項。啟用「自動重新整理」後,資訊主頁資料會每分鐘更新一次。這項功能與自訂時間範圍不相容。時間選取器會顯示預設選取的
1 day。如要變更時間範圍,請選取其他預先定義的時間範圍,或按一下「自訂」,然後定義開始和結束時間。目前系統只提供最近 30 天的資料。如要建立指向資訊主頁的絕對連結,請按一下「複製連結」按鈕。您可以將這個連結分享給擁有相同權限的其他 Cloud SQL 使用者。
如要為特定事件建立快訊,請按一下 「通知」。
如要顯示特定快訊,請按一下「註解」。
摘要資訊卡
下表說明系統洞察資訊主頁頂端顯示的摘要資訊卡。這些資訊卡會簡要概述執行個體在所選時間範圍內的健康狀態和效能。
| 摘要資訊卡 | 說明 |
|---|---|
| CPU 使用率 - P99 | P50 | 所選期間的 P99 和 P50 CPU 使用率值。 |
| 尖峰連線數量 | 所選期間內尖峰連線數量與最大連線數量的比率。如果上限數量最近已變更 (例如因執行個體縮放或手動變更 max_connections 設定),峰值連線數量可能會高於上限數量。 |
| 交易 ID 使用率 | 所選期間內最新的交易 ID 使用率值。 |
| 磁碟使用率 | 最新的磁碟使用率值。 |
| 記錄檔錯誤 | 使用者記錄的錯誤數量。 |
指標圖表
範例指標的圖表資訊卡如下所示。

每張圖表資訊卡的工具列都提供下列標準選項:
如要查看所選期間特定時刻的指標值,請將游標移至圖表上。
如要放大圖表,請按一下圖表,然後沿著 x 軸水平拖曳或沿著 y 軸垂直拖曳。如要還原縮放操作,請按一下「Reset zoom」。或者,按一下資訊主頁頂端的其中一個預先定義的時間範圍。縮放作業會同時套用至資訊主頁上的所有圖表。
如要查看其他選項,請按一下 more_vert「更多圖表選項」。大部分圖表都提供下列選項:
如要以全螢幕模式查看圖表,請按一下「以全螢幕模式查看」。如要退出全螢幕模式,請按一下「取消」。
隱藏或收合圖例。
下載圖表的 PNG 或 CSV 檔案。
在 Metrics Explorer 中查看。在 Metrics Explorer 中查看指標。選取 Cloud SQL 資料庫資源類型後,您可以在 Metrics Explorer 中查看其他 Cloud SQL 指標。
如要建立自訂資訊主頁,請按一下 edit「自訂資訊主頁」,然後為資訊主頁命名。或者,展開「預先定義」選單,然後選取現有的自訂資訊主頁。
如要查看指標圖表的詳細資料,請按一下「探索資料」query_stats。您可以在此篩選特定指標,並選擇圖表的顯示方式:

如要將這項自訂檢視畫面儲存為指標圖表,請按一下「儲存至資訊主頁」。
預設指標
下表說明 Cloud SQL 系統洞察資訊主頁預設顯示的 Cloud SQL 指標。
指標類型字串會遵循以下前置字串:cloudsql.googleapis.com/database/。
如要瞭解下列指標的最新發布階段,請參閱 Google Cloud 指標。
| 指標名稱和類型 | 說明 |
|---|---|
每秒新增連線數postgresql/new_connection_count
|
您在 PostgreSQL 適用的 Cloud SQL 執行個體中建立新連線的速率,以每秒建立的數量呈現。Cloud SQL 會計算並顯示每個資料庫的這項指標。 這項指標適用於 PostgreSQL 14 以上版本。 |
等待事件類型
postgresql/backends_in_wait
|
Cloud SQL for PostgreSQL 執行個體中,各個等候事件類型的連線數量。 |
等待事件postgresql/backends_in_wait
|
Cloud SQL for PostgreSQL 執行個體中的等候事件數量。資訊主頁會以「等待事件名稱」:「等待事件類型」顯示這項指標。 |
交易次數postgresql/transaction_count
|
在 PostgreSQL 適用的 Cloud SQL 執行個體中,處於 |
記憶體元件memory/components
|
資料庫可用的記憶體元件。每個記憶體元件的值會以百分比計算,表示資料庫可用的總記憶體。 |
備用資源最長延遲時間 (以位元組為單位)postgresql/external_sync/max_replica_byte_lag
|
在外部伺服器 (ES) 備用資源中,所有資料庫之間的最長複製延遲時間 (以位元組為單位)。 |
查詢延遲時間postgresql/insights/aggregate/latencies |
每個使用者和資料庫的匯總查詢延遲分布情形,按照 P99、P95 和 P50 分類。 僅適用於已啟用 查詢洞察的執行個體。 |
每個資料庫/使用者/用戶端位址的資料庫負載postgresql/insights/aggregate/execution_time |
每個資料庫、使用者或用戶端位址的累計查詢執行時間,也就是下列項目的總和:CPU 作業時間、I/O 等待時間、鎖定等待時間、程序內容變更,以及查詢執行作業中的所有程序排程。 僅適用於已啟用 查詢洞察的執行個體。 |
CPU 使用率cpu/utilization |
目前的 CPU 使用率 (以使用中的預留 CPU 百分比表示)。 |
依類型顯示的磁碟儲存空間disk/bytes_used_by_data_type
|
執行個體磁碟用量的詳細資料,按照 這項指標可協助您瞭解儲存空間成本。如要進一步瞭解儲存空間使用費,請參閱「儲存空間和網路定價」一文。 時間點復原 (PITR) 會使用預先寫入記錄檔 (WAL) 封存功能。這些記錄會定期更新,並使用儲存空間。預先寫入記錄會隨其相關的自動備份檔案一起自動刪除,這通常會在 7 天後發生。 如果預先寫入記錄的大小導致執行個體發生問題,您可以增加儲存空間大小,但磁碟用量中預先寫入記錄大小的增加可能只是暫時性的。為避免發生意料之外的儲存空間問題,Google 建議您在使用 PITR 時啟用自動增加儲存空間功能。 如要刪除記錄並復原儲存空間,您可以停用時間點復原功能。但是請注意,減少使用的儲存空間並不會縮小為執行個體佈建的儲存空間大小。 儲存空間用量指標會納入暫存資料。系統會在維護期間移除暫時性資料,並允許暫時性資料超過使用者定義的容量限制,以免發生磁碟空間不足的情況,且不會向使用者收費。 新建的資料庫會使用約 100 MB 的空間存放系統資料表和檔案。 |
依類型顯示的磁碟儲存空間disk/bytes_used_by_data_type
|
執行個體磁碟用量的詳細資料,按照 這項指標可協助您瞭解儲存空間成本。如要進一步瞭解儲存空間使用費,請參閱「儲存空間和網路定價」一文。 時間點復原會使用預先寫入記錄 (WAL) 封存功能。對於啟用即時還原功能的新 Cloud SQL 執行個體,或是在啟用 Cloud Storage 中儲存 WAL 記錄功能後啟用即時還原功能的現有執行個體,系統將不再將記錄儲存在磁碟上,而是儲存在與執行個體相同的 Cloud Storage 區域中。 如要查看執行個體的記錄是否儲存在 Cloud Storage 中,請檢查執行個體的 bytes_used_by_data_type 指標。如果 所有其他已啟用即時還原功能的現有執行個體,其記錄仍會儲存在磁碟上。我們會在稍後提供將記錄儲存在 Cloud Storage 中的變更。 在指定時間點復原作業中使用的預先寫入記錄,會連同相關聯的自動備份資料自動刪除,這通常會在 transactionLogRetentionDays 的值設定達到後發生。這是 Cloud SQL 為時間點復原保留的交易記錄天數,介於 1 到 7 天。 如果執行個體有預先寫入記錄檔,且儲存在 Cloud Storage 中,則記錄檔會儲存在與主要執行個體相同的區域。這類記錄儲存空間 (最長七天,即時還原功能的最大長度) 不會為每個執行個體產生額外費用。 如果執行個體已啟用時間點復原功能,且磁碟上預先寫入記錄的大小導致執行個體發生問題,請停用時間點復原功能,然後重新啟用,確保新記錄儲存在與執行個體相同區域的 Cloud Storage 中。這會刪除現有的預先寫入記錄,因此您必須先重新啟用時間點復原功能,才能執行時間點還原作業。不過,即使刪除現有的記錄,磁碟大小仍會維持不變。 為避免發生意外的儲存空間問題,建議您在使用時間點復原功能時,為所有執行個體啟用自動增加儲存空間。只有在執行個體啟用即時還原功能,且記錄儲存在磁碟上時,這項建議才適用。 如要刪除記錄並復原儲存空間,您可以停用時間點復原功能。不過,請注意,減少所使用的預寫記錄不會縮減為執行個體配置的磁碟大小。 儲存空間用量指標會納入暫存資料。系統會在維護期間移除暫時性資料,並允許暫時性資料超過使用者定義的容量限制,以免發生磁碟空間不足的情況,且不會向使用者收費。 新建的資料庫會使用約 100 MB 的空間存放系統資料表和檔案。 |
磁碟讀取/寫入作業disk/read_ops_count, disk/write_ops_count |
「讀取次數」指標代表磁碟提供的每秒讀取作業次數,其並非來自快取。您可以使用這項指標瞭解執行個體是否適合環境。如有需要,您可以改用較大的機器類型,從快取提供更多要求,並縮短延遲時間。 「寫入次數」指標則表示磁碟的寫入作業次數。即使應用程式處於非活動狀態,系統也會產生寫入活動,因為 Cloud SQL 執行個體 (不含備用資源) 會大約每秒寫入一次系統資料表。 |
連線數量 (按照狀態顯示)postgresql/num_backends_by_state |
按下列狀態分組的連線數量: 如要瞭解這些狀態,請參閱
|
每個資料庫的連線postgresql/num_backends |
資料庫執行個體保留的連線數量。 |
輸入/輸出位元組數network/received_bytes_count, network/sent_bytes_count |
與執行個體之間的往來網路流量,分別按照輸入位元組數 (已接收的位元組) 和輸出位元組數 (已傳送的位元組) 分類。 |
按類型細分的 I/O 等待時間postgresql/insights/aggregate/io_time |
SQL 陳述式的 I/O 等待時間細目,按讀取和寫入類型分類。 僅適用於已啟用 查詢洞察的執行個體。 |
不同資料庫的死結數postgresql/deadlock_count |
每個資料庫的死結數量。 |
區塊讀取數量postgresql/blocks_read_count |
從磁碟和緩衝區快取每秒讀取的區塊數量。 |
不同作業處理的資料列數postgresql/tuples_processed_count |
每項作業每秒處理的資料列數。 |
不同狀態的資料庫列數量postgresql/tuple_size |
每個資料庫狀態的資料列數。如果執行個體中的資料庫數量少於 50 個,Cloud SQL 就會回報這項指標。 |
存在時間最長的交易postgresql/vacuum/oldest_transaction_age |
阻擋 vacuum 作業的最舊交易存在時間。 |
WAL 封存replication/log_archive_success_count, replication/log_archive_failure_count |
每分鐘封存成功或失敗的預先寫入記錄檔數量。 |
交易 ID 使用率postgresql/transaction_id_utilization |
執行個體中使用的交易 ID 百分比。 |
各應用程式名稱的連線數量postgresql/num_backends_by_application |
Cloud SQL 執行個體的連線數量 (按照應用程式分組)。 |
擷取的資料列數量與傳回的資料列數量比較
|
如果傳回的資料列與擷取的資料列之間的差異太大,以致於其值無法以相同的比例顯示,則擷取的資料列值會顯示為 0,因為相較於傳回的資料列值,擷取的資料列值可忽略不計。 |
暫存資料大小postgresql/temp_bytes_written_count |
用於執行查詢和執行彙整和排序等演算法的資料總量 (以位元組為單位)。 |
暫存檔案postgresql/temp_files_written_count |
用於執行查詢和執行彙整和排序等演算法的暫存檔案數量。 |
此外,Cloud Logging 指標「Log entries by severity」 (logging.googleapis.com/log_entry_count) 會顯示錯誤和警告記錄項目的總數。
這些記錄項目擷取自資料庫記錄檔 postgres.log,以及含有資料存取資訊的 pgaudit.log。
詳情請參閱「Cloud SQL 指標」。
事件時間軸
資訊主頁會提供下列事件的詳細資料:
| 事件名稱 | 說明 | 作業類型 |
|---|---|---|
Instance restart |
重新啟動 Cloud SQL 執行個體 | RESTART |
Instance failover |
將高可用性 (HA) 主要執行個體手動容錯移轉至待命執行個體,該執行個體會成為主要執行個體。 | FAILOVER |
Instance maintenance |
表示執行個體目前處於維護狀態。維護作業通常會導致執行個體無法使用 1 到 3 分鐘。 | MAINTENANCE |
Instance backup |
執行執行個體備份。 | BACKUP_VOLUME |
Instance update |
更新 Cloud SQL 執行個體的設定。 | UPDATE |
Promote replica |
將 Cloud SQL 備用資源執行個體升級為主要執行個體。 | PROMOTE_REPLICA |
Start replica |
在 Cloud SQL 唯讀備用資源執行個體上啟動複製作業。 | START_REPLICA |
Stop replica |
停止 Cloud SQL 唯讀備用資源執行個體的複製作業。 | STOP_REPLICA |
Recreate replica |
重新建立 Cloud SQL 複本執行個體的資源。 | RECREATE_REPLICA |
Create replica |
建立 Cloud SQL 備用資源執行個體。 | CREATE_REPLICA |
Data import |
將資料匯入 Cloud SQL 執行個體。 | IMPORT |
Instance export |
將資料從 Cloud SQL 執行個體匯出至 Cloud Storage 值區。 | EXPORT |
Restore backup |
還原 Cloud SQL 執行個體的備份。這項作業可能會導致執行個體重新啟動。 | RESTORE_VOLUME |