guest post by William Waites
The previous post introduced the plumbing calculus: typed channels, structural morphisms, two forms of composition, and agents as stateful morphisms with a protocol for managing their state. The examples were simple. This post is about what happens when the algebra handles something genuinely complex.
To get there, we need to understand a little about how large language models work. These models are sequence-to-sequence transducers: a sequence of tokens comes in, a sequence comes out. Text is tokenised and the model operates on the tokens.
From the outside, the morphism is simple: !string → !string. A message goes in, a message comes out. But the client libraries (the code that calls the LLM provider) maintain the conversation history and send it back with every call. The actual morphism is
(!string, ![Message]) → (!string, ![Message]): the input message and the accumulated history go in, the response and the updated history come out. The history feeds back. This is a trace in the sense of traced monoidal categories: the feedback channel is hidden from the user, who sees only !string → !string.
Crucially, the model has a limited amount of memory. It is not a memoryless process, but the memory it has is not large: 200,000 tokens for current models, perhaps a million for the state of the art. This sounds like a lot. It is not. An academic paper is roughly 10,000 tokens. A literature review that needs to work with thirty papers has already exceeded the context window of most models, and that is before the model has produced a single word of output.
If you have used any of these agent interfaces, you will have noticed that after talking back and forth for a while, the agent will compact. This is a form of memory management. What is happening is that some supervisory process has noticed the context window filling up, and has intervened to shorten its contents. A naïve approach is to truncate: discard everything before the last N exchanges. A better approach is to feed the entire context to another language model and ask it to summarise, then put the summary back.
This is normally done by specialised code outside the agent, invisible to it.
How to manage agent memory well is an active research area. We do not, in general, do it very well. Truncation loses information. Summarisation loses nuance. Pinning helps but the right pinning strategy depends on the task. These are open questions, and to make progress we need to be able to experiment with different schemes and mechanisms: express a memory management strategy, test it, swap it for another, compare. Not by recompiling specialised code or hardcoding behaviour, but by writing it down in a language designed for exactly this kind of composition. Memory management should be a plumbing program: modular, type-checked, swappable.
So we built an implementation of compaction using the plumbing calculus, and the first thing we did was test it. I ran the protocol on a very short cycle: a single message caused a compaction, because the threshold was set to zero for testing. The compressor fired, produced a summary, rebuilt the agent’s context. The logs showed [compressor] 3404 in / 541 out. The protocol worked.
Then I asked the agent: "have you experienced compaction?"
The agent said no. It explained what compaction is, accurately. Said it hadn’t happened yet. It was confident.
I asked: "do you have a context summary in your window?"
Yes, it said, and described the contents accurately.
"How did that context summary get there if you have not yet compacted?"
The agent constructed a plausible, confident, and completely wrong explanation: the summary was "provided to me by the system at the start of this conversation" as a "briefing or recap." When pressed, it doubled down:
"The context-summary is not evidence that compaction has occurred. It’s more like a briefing or recap that the system gives me at the start of a conversation session to provide continuity."
The agent was looking at the direct evidence of its own compaction and confidently explaining why it was not compaction. We will return to why it gets this wrong, and how to fix it. But first: how do we build this?
The compacting homunculus
At a high level, it works like this. An agent is running: input comes in, output goes out. Together with the output, the agent emits a telemetry report. The telemetry includes token counts: with each transaction, the entire train of messages and responses is sent to the LLM provider, and back comes a response together with a count of the tokens that went in and the tokens that came out. Our agent implementation sends this telemetry out of the telemetry port to anybody who is listening.
The construction involves a second agent. This second agent is a homunculus: the little man who sits on your shoulder and watches what your mind is doing. Here is the topology:

The homunculus listens to the telemetry and says: the memory is filling up. The token count has crossed a threshold. It is time to compact. And then it acts:
• Send pause to the agent’s control port. Stop accepting input.
• Send get memory. The agent produces the contents of its context window.
• Summarise that memory (using another LLM call).
• Send set memory with the compacted version.
• Send resume. The agent continues processing input.
Each step requires an acknowledgement before the next can proceed. This is a protocol: pause, acknowledge, get memory, here is the memory, set memory, acknowledge, resume, acknowledge.
It is possible to express this directly in the plumbing calculus, but it would be painfully verbose. Instead, we use session types to describe the protocol. This is not pseudocode. There is a compiler and a runtime for this language. Here is the protocol:
protocol Compaction =
send Pause . recv PauseAck .
send GetMemory . recv MemoryDump .
send SetMemory . recv SetMemoryAck .
send Resume . recv ResumeAck . end
The protocol is eight lines. It reads as a sequence of steps:
send, receive, send, receive, and so on. The compiler knows what
types each step carries. Now we wire it up:
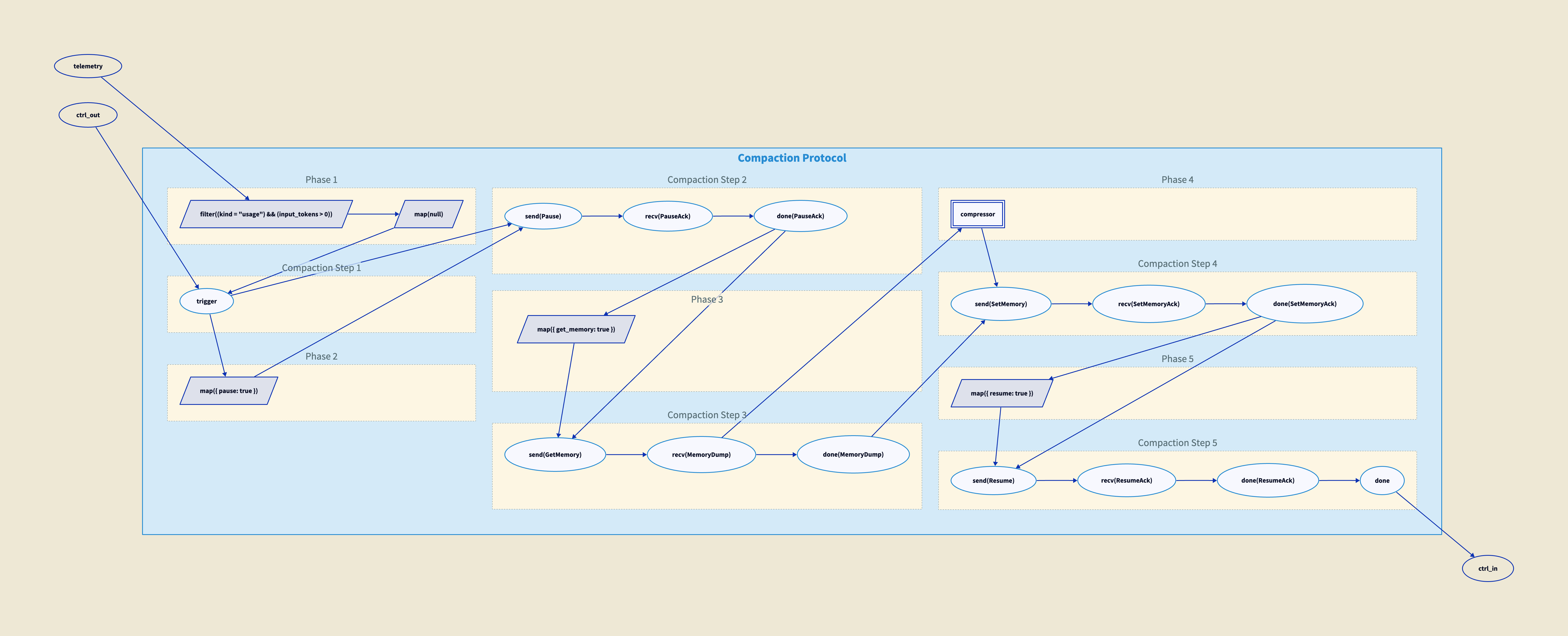
let compact : (!CtrlResp, !json) -> !CtrlCmd =
plumb(ctrl_out, telemetry, ctrl_in) {
(ctrl_out, ctrl_in) Compaction as session
telemetry
; filter(kind = "usage" && input_tokens > 150000)
; map(null) ; session@trigger
session@trigger ; map({pause: true})
; session@send(Pause)
session@done(PauseAck) ; map({get_memory: true})
; session@send(GetMemory)
session@recv(MemoryDump) ; compressor
; session@send(SetMemory)
session@done(SetMemoryAck) ; map({resume: true})
; session@send(Resume)
}
The first line binds the protocol to the agent’s control ports:
(ctrl_out, ctrl_in) <-> Compaction as session.
This says: the Compaction protocol runs over the control channel, and we refer to it as session. The telemetry line is the trigger: when token usage crosses a threshold, the protocol begins. Each subsequent line is one step of the protocol, wired to the appropriate control
messages.
Here is a direct depiction of the protocol as wired. You can trace it through:
And here is how we wire the homunculus to the agent:
let main : !string -> !string =
plumb(input, output) {
let ctrl : !CtrlCmd = channel
let ctrl_out : !CtrlResp = channel
let telem : !json = channel
spawn bot(input=input, ctrl_in=ctrl,
output=output, ctrl_out=ctrl_out,
telemetry=telem)
spawn compact(ctrl_out=ctrl_out,
telemetry=telem, ctrl_in=ctrl)
}
The main morphism takes a string input and produces a string output. Internally, it creates three channels (control commands, control responses, telemetry) and spawns two processes: the bot agent and the compact homunculus. The homunculus listens to the bot’s telemetry and control responses, and sends commands to the bot’s control input. The bot does not know the homunculus exists. It just receives control messages and responds to them.
There are two nested traces here. The first is the one from before, inside the agent: messages go in, the output accumulates with everything that came before, and the whole history feeds back on the next turn. We do not see this trace. It is hidden inside the client library. The second trace is the one we have just built: the homunculus. What goes around the outer loop is control: telemetry flows out, commands flow in, acknowledgements come back. The memory dump passes through the control channel at one point in the protocol, but the feedback path is control, not conversation history. Nested traces compose; the algebra has identities for this and it is fine. But they are different loops carrying different things.
Session types as barrier chains
The connection between the protocol above and what the compiler actually produces is the functor from session types into the plumbing calculus. This functor works because of barrier.
Why do we need the barrier? Because the protocol is about sending a message and waiting for a response. We can send a message, but we need the response to arrive before we proceed. The barrier takes two streams, one carrying the "done" signal and one carrying the response, and synchronises them into a pair. Only when both are present does the next step begin.
Each session type primitive has a direct image in the plumbing category, and the structure is prettier than it first appears. The primitives come in dual pairs:
In the diagrams below, session types are on the left in blue; their images in the plumbing calculus are on the right in beige.
• send and recv are dual. They map to map and filter, which are also dual: send wraps the value with map, then synchronises via barrier with the done signal from the previous step. Recv filters the control output by step number, synchronises via barrier, then extracts the payload with map.
• select and offer are dual. They map to tag and case analysis, which are also dual: select tags the value with a label via map, synchronises via barrier, and routes to the chosen branch chain. Offer copies the control output and filters each copy by label, routing to the appropriate branch chain.

• The sequencing operator (.) maps to a barrier chain. Each send-then-recv step becomes a barrier that synchronises the outgoing message with the incoming acknowledgement, and these barriers chain together to enforce the protocol ordering.

• rec maps to a feedback loop: merge takes the initial
arm signal and the last done signal from the previous iteration, feeds them into the barrier chain body, and copy at the end splits done into output and feedback. The trigger serialisation gate starts
• end is implicit: the chain simply stops. Discard handles any remaining signals.

This mapping is a functor. It is total: every session type primitive has an image in the plumbing category, using only the morphisms we already have. Session types are a specification language; the plumbing calculus is the execution language. The compiler translates one into the other.
The reason we do this becomes obvious from the diagram below. It is scrunched up and difficult to look at. If you click on it you can get a big version and puzzle it out. If you squint through the spaghetti, you can see that it does implement the same compaction protocol above. We would not want to implement this by hand. So it is nice to have a functor. If you have the patience to puzzle your way through it, you can at least informally satisfy yourself that it is correct.

Document pinning
There is another feature we implement, because managing the memory of an agent is not as simple as just compressing it.
The problem with compression is that it is a kind of annealing. As the conversation grows, it explores the space of possible conversation. When it gets compacted, it is compressed, and that lowers the temperature. Then it grows again, the temperature rises, and then it is compressed again. With each compression, information is lost. Over several cycles of this, the agent can very quickly lose track of where it was, what you said at the beginning, what it was doing.
We can begin to solve this with document pinning. The mechanism is a communication between the agent and its homunculus, not shown in the protocol above. It is another protocol. The agent says: this document that I have in memory (technically a tool call and response, or just a document in the case of the prompts), pin it. What does that mean? When we do compaction, we compact the contents of memory, but when we replace the memory, we also replace those pinned documents verbatim. And of course you can unpin a document and say: I do not want this one any more.
Either the agent can articulate this or the user can. The user can say: you must remember this, keep track of this bit of information. And the agent has a way to keep the most important information verbatim, without it getting compacted away.
This accomplishes two things.
First, it tends to keep the agent on track, because the agent no longer loses the important information across compaction cycles. The annealing still happens to the bulk of the conversation, but the pinned documents survive intact.
Second, it has to do with the actual operation of the underlying LLM on the GPUs. When you send a sequence of messages, this goes into the GPU and each token causes the GPU state to update. This is an expensive operation, very expensive. This is why these things cost so much. What you can do with some providers is put a cache point and say: this initial sequence of messages, from the beginning of the conversation up until the cache point, keep a hold of that. Do not recompute it. When you see this exact same prefix, this exact same sequence of messages again, just load that memory into the GPU directly. Not only is this a lot more efficient, it is also a lot cheaper, a factor of ten cheaper if you can actually hit the cache.
So if you are having a session with an agent and the agent has to keep some important documents in its memory, it is a good idea to pin them to the beginning of memory. You sacrifice a little bit of the context window in exchange for making sure that, number one, the information in those documents is not forgotten, and number two, that it can hit the cache. This is explained in more detail in a separate post on structural prompt preservation.
The agent that doesn’t know itself
Why does the agent get this wrong? In one sense, it is right. It has not experienced compaction. Nobody experiences compaction. Compaction happens in the gap between turns, in a moment the agent cannot perceive. The agent’s subjective time begins at the summary. There is no "before" from its perspective.
The summary is simply where memory starts. It is like asking someone "did you experience being asleep?" You can see the evidence, you are in bed, time has passed. But you did not experience the transition.
The <context-summary> tag is a structural marker. But interpreting it as evidence of compaction requires knowing what the world looked like before, and the agent does not have that. It would need a memory of not having a summary, followed by a memory of having one. Compaction erases exactly that transition.
Self-knowledge as metadata
The fix is not complicated. It is perfectly reasonable to provide, along with the user’s message, self-knowledge to the agent as metadata. What would it be useful for the agent to know?
The current time. The sense of time that these agents have is bizarre. We live in continuous time. Agents live in discrete time. As far as they are concerned, no time passes between one message and the next. It is instantaneous from their point of view. You may be having a conversation, walk away, go to the café, come back two hours later, send another message, and as far as the agent is concerned no time has passed. But if along with your message you send the current time, the agent knows.
How full the context window is. The agent has no way of telling, but you can provide it: this many tokens came in, this many went out.
Compaction cycles. So the agent knows how many times it has been compacted, and can judge the accuracy of the contents of its memory, which otherwise it could not do.
With the compaction counter, the agent immediately gets it right:
"Yes, I have experienced compaction. According to the runtime context, there has been 1 compaction cycle during this session."
No hedging, no confabulation. Same model, same prompts, one additional line of runtime context.
Context drift
This matters beyond the compaction story, because many of the failures we see in the news are context failures, not alignment failures.
While we were writing this post, a story appeared in the Guardian about AI chatbots directing people with gambling addictions to online casinos. This kind of story is common: vulnerable people talking to chatbots, chatbots giving them bad advice. The response of the industry is always the same: we need better guardrails, better alignment, as though the chatbots are badly aligned.
I do not think that is what is happening. What is happening is a lack of context. Either the chatbot was never told the person was vulnerable, or it was told and the information got lost. Someone with a gambling addiction may start by saying "I have a gambling problem." Then there is a four-hour conversation about sports. Through compaction cycles, what gets kept is the four hours of sports talk. The important bit of information does not get pinned and does not get kept. Context drift. By the time the user asks for betting tips, the chatbot no longer knows it should not give them.
The way to deal with this is not to tell the language model to be more considerate. The way to deal with it is to make sure the agent has enough information to give good advice, and that the information does not get lost. This is what document pinning is for: pinned context survives compaction, stays at the top of the window, cannot be diluted by subsequent conversation. This is discussed further in a separate post on structural prompt preservation.
But pinning is only one strategy. The field is in its infancy. We do not really know the right way to manage agent memory, and we do not have a huge amount of experience with it. What we are going to need is the ability to experiment with strategies: what if compaction works like this? What if pinning works like that? What if the homunculus watches for different signals? Each of these hypotheses needs to be described clearly, tested, and compared. This is where the formal language earns its keep. A strategy described in the plumbing calculus is precise, checkable, and can be swapped out for another without rewriting the surrounding infrastructure. We can experiment with memory architectures the way we experiment with any other part of a system: by describing what we want and seeing if it works.
Why has nobody done this?
When the first draft of this post was written, it was a mystery why the field had not thought to give agents self-knowledge as a routine matter: what they are doing, who they are talking to, what they should remember. Prompts are initial conditions. They get compacted away. There are agents that save files to disc, in a somewhat ad hoc way, but we do not give them tools to keep track of important information in a principled way.
Contemporaneously with this work, some providers have started to do it. For example, giving agents a clock, the ability to know what time it is. This is happening now, in the weeks between drafting and publication. The field is only now realising that agents need a certain amount of self-knowledge in order to function well. The compressed timeline is itself interesting: the gap between "why has nobody done this?" and "everybody is starting to do this" was a matter of weeks.
The mechanisms we have presented here allow us to construct agent networks and establish protocols that describe rigorously how they are meant to work. We can describe strategies for memory management in a formal language, test them, and swap them out. And perhaps beyond the cost savings and the efficiency increases, the ability to experiment clearly and formally with how agents manage their own memory is where the real value lies.



 Posted by John Baez
Posted by John Baez 







 is
is  into it, and replace that copy of
into it, and replace that copy of  This deserves to be explained more clearly, but right now I just want to point out that in our software, we specify each rewrite rule by giving its morphisms
This deserves to be explained more clearly, but right now I just want to point out that in our software, we specify each rewrite rule by giving its morphisms 
 is a morphism called
is a morphism called 





 with:
with:

 in our collection, a timer
in our collection, a timer  This is a stochastic map
This is a stochastic map![T_i \colon [0,\infty) \to [0,\infty]](https://s0.wp.com/latex.php?latex=T_i+%5Ccolon+%5B0%2C%5Cinfty%29+%5Cto+%5B0%2C%5Cinfty%5D+&bg=ffffff&fg=333333&s=0&c=20201002)
 we get a probability measure
we get a probability measure  on
on ![[0,\infty].](https://s0.wp.com/latex.php?latex=%5B0%2C%5Cinfty%5D.&bg=ffffff&fg=333333&s=0&c=20201002)
 to mean a randomly chosen element of
to mean a randomly chosen element of ![[0,\infty]](https://s0.wp.com/latex.php?latex=%5B0%2C%5Cinfty%5D&bg=ffffff&fg=333333&s=0&c=20201002) distributed according to the probability measure
distributed according to the probability measure  We call
We call  we should wait until we apply the rewrite rule
we should wait until we apply the rewrite rule  The time
The time
 If you give me the initial state of the world
If you give me the initial state of the world  the stochastic C-set rewriting system will tell you how to compute the state of the world at all later times. But this computation involves randomness.
the stochastic C-set rewriting system will tell you how to compute the state of the world at all later times. But this computation involves randomness. We look for all matches to patterns
We look for all matches to patterns  in the initial state
in the initial state  For each match we compute a wait time
For each match we compute a wait time ![w_i(t) \in [0,\infty]](https://s0.wp.com/latex.php?latex=w_i%28t%29+%5Cin+%5B0%2C%5Cinfty%5D&bg=ffffff&fg=333333&s=0&c=20201002) and then the rewrite time
and then the rewrite time  but right now
but right now  is the first time the state of the world can change. We change it by applying the rewrite rule
is the first time the state of the world can change. We change it by applying the rewrite rule  to the state of the world
to the state of the world  and its corresponding match from our table.
and its corresponding match from our table. we add that match and its rewrite time
we add that match and its rewrite time  to our table.
to our table. At that time, we apply the corresponding rewrite rule to the state
At that time, we apply the corresponding rewrite rule to the state  , getting some new C-set
, getting some new C-set  We also cross off the rewrite time
We also cross off the rewrite time  and its corresponding match from our table.
and its corresponding match from our table. here means the wait time can depend on when we start the timer. And the fact that this stochastic map takes values in
here means the wait time can depend on when we start the timer. And the fact that this stochastic map takes values in  However, in this case I am confused about how we should update our table of wait times as the state of the world changes. So I decided to postpone discussing this generalization!
However, in this case I am confused about how we should update our table of wait times as the state of the world changes. So I decided to postpone discussing this generalization!
