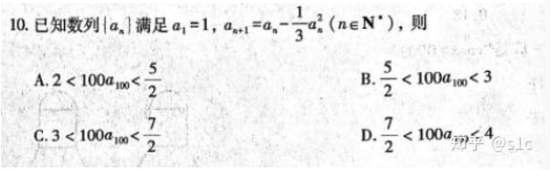| 送交者: sky9[♂☆★★中和★★☆♂] 于 2025-01-26 8:26 已读 953 次 2 赞 | sky9的个人频道 |
中国人工智能公司深度求索(DeepSeek)近期相继推出开源人工智能(AI)模型DeepSeek-V3和DeepSeek-R1,引起了硅谷同行以及西方媒体的高度关注。
1月23日,英媒《金融时报》刊文《深度求索等中国初创企业正在挑战全球AI巨头》,对于深度求索给予高度评价。文章称,该公司推出的V3模型震惊了国际科技界,其性能可与资金更雄厚的OpenAI等美国竞争对手相媲美;R1模型给人留下了深刻印象,是其进军AI推理领域的尝试。
美国南加州大学古尔德法学院法学教授张湖月(Angela Zhang)在文中提到,深度求索并非孤例。自去年年中以来,阿里巴巴、腾讯、字节跳动等中国科技公司一直在稳扎稳打,逐步缩小与美国同行的差距,在能力上与他们匹敌,在成本效率上超越他们。
“中国在效率方面的成就并非偶然。这是中国对美国及其盟友不断升级的出口限制的直接回应。”张湖月认为,“美国限制中国获取先进的AI芯片,却无意中刺激了中国的创新。”
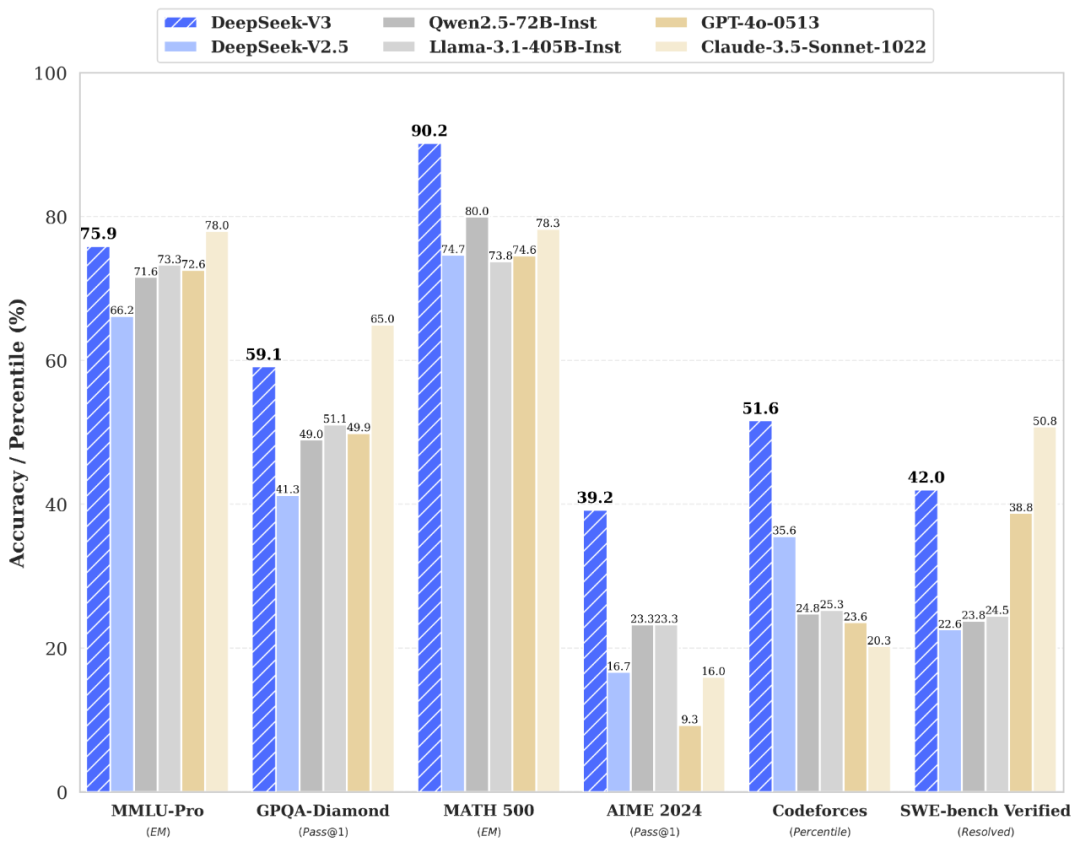
Deepseek-V3与多个国内外大模型的测试数据对比“Deepseek”公众号 文章观察到,在美国打压中企并限制AI芯片对华出口后,为了减少对海外高端芯片的依赖,中国AI公司在算法、架构和训练策略方面尝试了新方法。许多公司采用了“混合专家”方法,专注于针对特定数据进行训练的小型AI模型。这些方法可以在减少计算资源的同时提供强大的结果。
DeepSeek-V3模型体现了这种方法的成功。根据其技术报告,该模型使用由英伟达H800 GPU驱动的数据中心进行训练。据介绍,深度求索公司仅用两个月就完成了训练,成本为550万美元,仅为OpenAI等美国公司所花费金额的一小部分。
深度求索公司还大幅降低了推理成本,因此获得了“AI届拼多多”的绰号。这一突破意义深远,挑战了人们普遍持有的假设,即尖端AI需要大量计算能力和高达数十亿美元的资金。深度求索展示了软件的独创性如何抵消硬件的限制。
文章称,这同时暴露了美国旨在阻碍中国AI发展的出口管制的局限性。虽然这些措施可能会造成短期干扰,但随着中国不断创新以适应,其影响只会逐渐减弱。
“对于美国政策制定者来说,一个难以接受的事实是,严格的出口管制迫使中国科技公司变得更加自力更生,从而推动了原本可能不会发生的突破。”文章如此写道。
文章认为,美国对华限制,“在不经意间”提供了一个强大的商业激励,促使中国私营部门填补AI这一空白。尽管美国通常在开创性研究中占据主导地位,但中国公司在执行力、价格承受能力和产品推广方面表现出色。这一点已在电子商务、电动汽车、太阳能(4.390, 0.02, 0.46%)电池板和电池等领域得到了生动体现。
“深度求索的崛起生动地提醒我们,限制可以促进创新。”文章最后向美国政府提出疑问,“对于特朗普的新政府来说,这提出了一个令人不安的问题:对中国实施越来越严厉的制裁是否会适得其反,加速他们原本想要压制的进步?”
值得注意的是,张湖月并非唯一一个提出上述疑问的学者。
“深度求索的诞生,说明了为什么特朗普很难打赢贸易战。”1月9日,美国乔治梅森大学经济系教授泰勒·考恩在彭博社刊文称,由于美国限制对华出口芯片,深度求索等中企无法获得最新的尖端芯片,因此不得不寻找其他更便宜的方法来训练其模型,并“间接导致了中国重要创新的出现”。
考恩在文中引用了奥地利经济学家路德维希·米塞斯的一句话:“政府干预会产生重要的、意想不到的次生后果。”他表示,要看一项政策是否奏效,不仅要考虑其直接影响,也要看它的二阶甚至三阶影响。
22日,前《纽约时报》专栏作者克雷格·史密斯在美国《福布斯》杂志刊文称,深度求索的成功,体现了中国AI创新者是如何挑战现状的。他同样认为,美国的出口管制旨在减缓中国AI的发展,但这可能无意中刺激了创新,中企被迫寻找创造性的解决方案,以更少的投入实现更多的成果。
史密斯预测称,随着中国继续投资和推动开源AI发展,同时应对出口管制带来的挑战,全球技术格局可能会进一步改变权力动态、合作模式和创新轨迹。这一战略的成功可能使中国成为塑造AI未来的主导力量,对技术进步、经济竞争力和地缘政治影响力产生深远影响。
不久前,深度求索公司创始人梁文锋接受媒体采访时指出:“在颠覆性的技术面前,闭源形成的护城河是短暂的。即使OpenAI闭源,也无法阻止被别人赶超。”
深度求索的迅速崛起,引起了美国媒体和硅谷的警惕。 6park.com
Scale AI首席执行官亚历山大·王谈深度求索AI新模型 视频截图 当地时间22日,微软首席执行官萨蒂亚·纳德拉在瑞士达沃斯世界经济论坛上表示:“深度求索的新模型非常令人印象深刻,他们不仅有效地开发出一种开源模型,实现了推理时间计算,而且计算效率极高。”他强调:“我们应该非常认真地对待中国的发展。”
美国AI科技公司Scale AI首席执行官亚历山大·王(Alexandr Wang)23日接受美国消费者新闻与商业频道(CNBC)采访时说,中国已凭借深度求索推出的开源模型迅速赶超美国。他表示:“我们发现,深度求索模型表现最佳,大致与美国最好的模型相当。”
亚历山大·王认为中美间正在进行“AI战争”,并补充说,中国在AI领域拥有比英伟达更强大的人才储备。他说:“美国将需要大量的计算能力和基础设施。我们需要释放美国的能量来推动AI繁荣。”
24日,CNBC再次发文称,深度求索的AI模型“威胁美国在AI领域的主导地位”。文章表示,深度求索花费两个月和约500万美元完成了V3模型的构建,引起了人们对于美国在AI领域的全球领先地位正在缩小的担忧,并对大型科技公司在建设AI模型和数据中心方面的巨额投入提出了质疑。 6park.com
原谅我之前的蔑视,当时我随手打开deepseek的深度思考问他这个问题: 6park.com
确实是用了深度思考,但是如思考 结果有点失望,直到今天我找到一个题目:
本文只是使用体验性质,纯主观,主要是我真的被惊艳到了。这也是我写的第一篇文章,请读者多担待。
题目是: 6park.com
题目原稿
看到这里的读者有兴趣的不妨拿出纸笔算一下,我设计的这个题是可以不用计算器得出答案的。
题目背景:在笔者上高中的时候,浙江月考和高考的最后一题喜欢考数列相关的题,给递推公式,然后给出选项回答第100项在哪个区间,下面是22年的高考题。笔者因为高三无聊,所以专门研究这类题目,然后自制了一道21年浙江压轴选择的加强版,当时在高中可谓是无人能解。 6park.com
22年浙江高考压轴题
首先,我先把22年高考原题丢给了deepseek r1,不出我意料,这两个东西是轻松秒杀了。 6park.com
展示部分过程
这一下让我来了兴致,我翻箱倒柜找出我自己手搓的加强版题目,分别丢给了o1-preview和deepseek r1,结果非常的amazing啊。
先说o1-preview,cot了一堆长篇大论的东西,结果最后分析的是一坨,前 101 项的和准确值是9.014259310455035,给我估成 5.19 去了,基本上是离答案甚远。 6park.com
o1-preview
然后我丢给了 o1-mini,这次它换了个办法,可惜答案依旧在题目允许的误差之外。 6park.com
o1-mini
接下来是deepseek r1出场的时机了: 6park.com
半步成神
这个deepseek踌躇了好一会,最后通过某种奇技淫巧(事实上和出题者的思路相似),得到了 8.625 的近似值,在题目误差范围之内,但是,他没能完全理解题目里面“最接近”的含义,选择了 8 这个选项,我的评价是:半步成神!
高考、月考题目中的类似题的正解当然是严格证明上下界,但是我作为学生、出题人来说,最一开始想的也是通过抓住数列的渐进增长趋势来以高精度拟合一个不精确的解,然后自信选择这个解接近的区间。这种思路都被deepseek学明白了,确实令人震惊。
震惊之余,我又试了一次 6park.com
还是半步成神
得到相似的结果,估算误差在题目允许范围之内,但是还是没有理解“最接近”的意思(看来还是我胜之半子
后记:这个题是我根据高考题原创的题,之前绝对没有被泄露过,虽然这种题是有所谓通解的,但是研究的人少,网上的资料也少(此为个人臆断),而且我这题算是“变态”版,普通高中生没有一些“高观点”做不出来。由此,我个人足以相信deepseek r1的推理/解题水平已经很高了,至少是秒杀高考的级别。不过看上去deepseek的估算很精细,但是就是没有仔细看题目里“最接近”的选项,也许是推理太长了,稍微有点忘了题干?反正是能够干翻o1-preview和o1-mini的水平了。